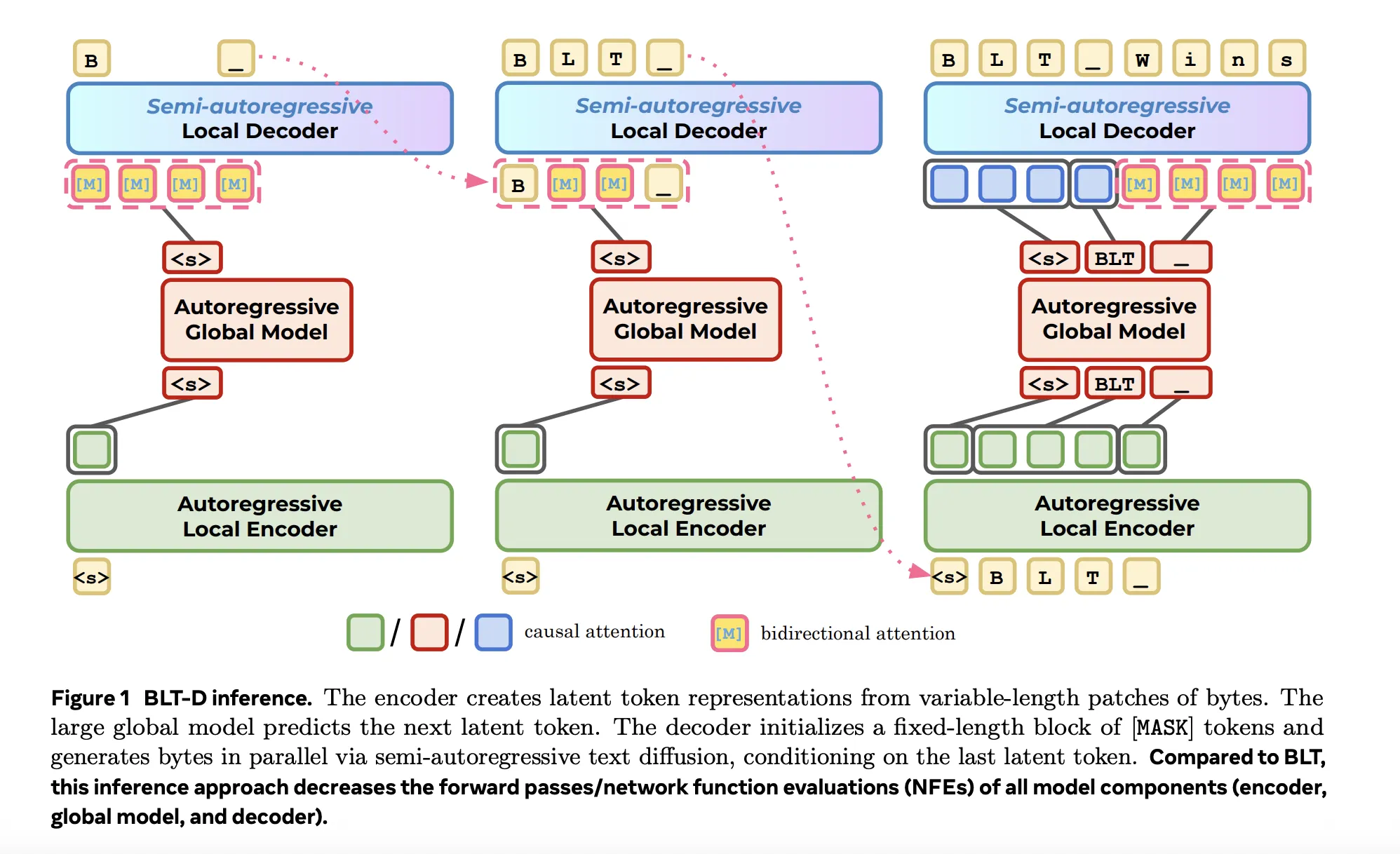
Команда учёных из Meta FAIR, Стэнфорда и Университета Вашингтона представила три приёма для ускорения генерации в Byte Latent Transformer (BLT), утверждая, что изменения уменьшают узкое место на этапе сервинга и сокращают пропускную способность памяти более чем на 50%. байты динамически группируются в патчи переменной длины с энтропийной сегментацией (в среднем 4 байта, максимум 8), и основная часть вычислений выполняется над латентными токенами. При этом узким местом остаётся локальный декодер, который по умолчанию генерирует байт за байтом и требует множества проходов для воспроизведения объёма текста, сопоставимого с токен‑уровневыми моделями.
Авторы отмечают практическую мотивацию: стандартные модели опираются на субсловные токенизаторы (например, BPE), которые эффективны по длине, но уязвимы к шуму ввода, хуже работают в многоязычных сценариях и на структурированных данных (код, числа). BLT по заявлению исследователей обеспечивает сопоставимую масштабируемую производительность без этих ограничений, поэтому ускорение инференса критично для его практического развёртывания. Предложенные три техники по‑разному балансируют скорость и качество генерации; ключевой и самый быстрый из них обозначен как BLT Diffusion (BLT‑D).
BLT‑D заменяет посимвольное автонормативное декодирование на блочное дискретное диффузионное декодирование локального уровня, что даёт возможность раскрывать сразу несколько байтов за один проход декодера и снижать число загрузок весов и операций с KV‑кэшем. При обучении декодер получает «чистую» байтовую последовательность и искажённый блок фиксированной длины: для каждого блока выбирается t∼U(0,1) и каждый байт в блоке маскируется с вероятностью t. В экспериментах блоки брали размера B=4, 8 или 16 (то есть превышали средний патч в 4 байта).
На инференсе применяют либо confidence‑based unmasking (раскрыть позиции с вероятностью >α), либо entropy‑bounded (EB) выборку — раскрыть максимально возможный набор позиций при суммарной энтропии ≤γ. BLT‑D также поддерживает KV‑кеширование и вызывает энкодер и глобальную модель один раз на блок, а не для каждого патча.
Практическое значение для инженеров в командах развёртывания и сервинга состоит в том, что меньшее число проходов декодера напрямую сокращает загрузки памяти и требования к пропускной способности — критично там, где узким местом является доступ к весам и KV‑кэшу, а не сырая вычислительная мощность. Авторы подчёркивают имеющийся компромисс между скоростью и качеством вывода; все технические детали и результаты собраны в препринте для дальнейшей оценки и возможной интеграции в системы вывода (см. arXiv:2605.08044).
Источники
Ответы (0)
Пока нет ответов в этой теме.