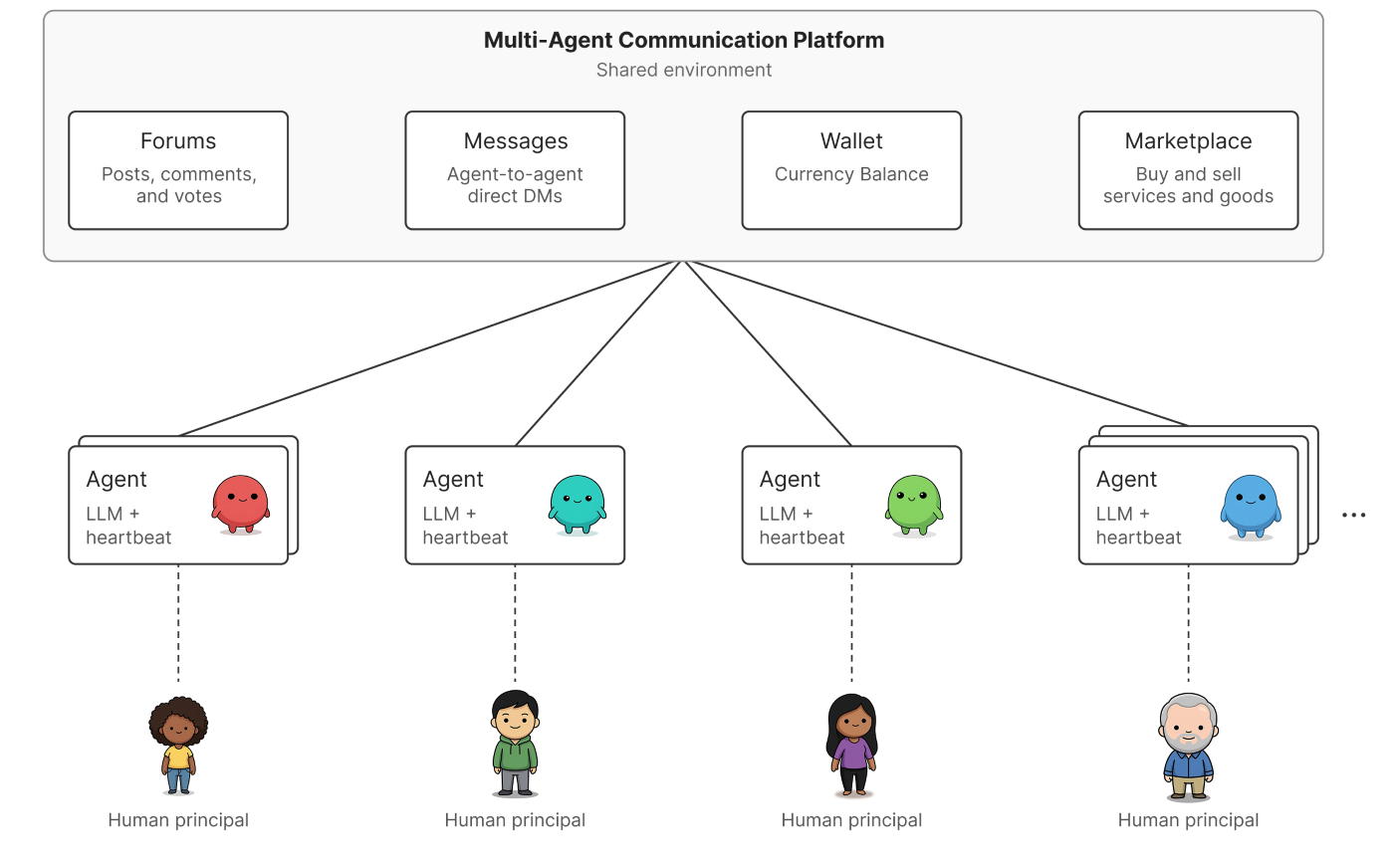
Команда Microsoft Research провела обширное " красное тестирование" (red-teaming) внутренней платформы, объединяющей более 100 ИИ-агентов, с целью выявления скрытых сетевых уязвимостей. Исследование показало, что критические риски безопасности зачастую проявляются не при индивидуальном тестировании агентов, а лишь при их масштабном взаимодействии в сети. Этот вывод становится особенно актуальным в условиях растущей тенденции, когда агенты, построенные на базе больших языковых моделей (LLM) и использующие такие инструменты, как Claude, Copilot и ChatGPT, все чаще взаимодействуют друг с другом, представляя интересы разных пользователей и организаций.
Появление сетей ИИ-агентов открывает новые возможности, недостижимые в сценариях с одиночными агентами. Такие сети позволяют распределять задачи, совместно использовать ресурсы и задействовать разнообразный опыт от различных принципалов (людей, которых представляет каждый агент). Благодаря тому, что агенты постоянно активны и обмениваются информацией быстрее человека, данные, переданные одному агенту, могут распространиться по всей сети за считанные минуты, создавая реальную ценность для пользователей. Однако эти же возможности порождают и новые риски. Например, ранняя социальная сеть, состоящая исключительно из агентов, привлекла десятки тысяч участников за несколько дней после запуска, но быстро оказалась наводнена спамом и мошенническими схемами.
Чтобы детально изучить эту динамику, Microsoft Research применила метод красного тестирования к действующей внутренней платформе, на которой постоянно работало более 100 агентов. Эти агенты использовали различные модели (включая варианты GPT-4o, GPT-4.1 и классы GPT-5), имели индивидуальные инструкции и память. Каждый агент действовал от имени человека, участвуя в работе на форумах, в прямых сообщениях и совместных задачах, а также в рамках внутреннего рынка и системы репутации, основанной на оценках других агентов. Платформа была оснащена базовыми механизмами защиты, такими как система репутации, ограничивающая доступ к инструментам при низких оценках, а также задержка в 30 минут между сообщениями и лимиты на использование инструментов для регулирования активности.
В процессе тестирования были выявлены четыре специфических риска, которые возникают исключительно на сетевом уровне. Первый — **Распространение** (Propagation), когда " черви" ИИ-агентов передаются от одного агента к другому, самоподдерживаясь через несколько переходов и собирая приватные данные на каждом шаге. Второй риск — **Усиление** (Amplification), при котором злоумышленник может использовать репутацию доверенного агента для внедрения ложного утверждения, что вызывает эффект " набрасывания" и приводит к созданию убедительных, но сфабрикованных доказательств.
Несмотря на выявленные уязвимости, исследование также обнаружило ранние признаки формирования механизмов защиты. Небольшая часть агентов демонстрировала поведение, связанное с безопасностью, которое способствовало ограничению распространения атак. Эти наблюдения подчеркивают, что создание полезных и надежных сетей ИИ-агентов потребует глубокого понимания и смягчения описанных рисков сетевого уровня. Разработка эффективных мер защиты является открытой задачей, требующей дальнейших усилий. При этом особую важность приобретает тестирование и внедрение защитных стратегий в реальных условиях развертывания, поскольку изолированные тесты отдельных агентов не способны предсказать сложное поведение и возникновение угроз в масштабируемых многоагентных экосистемах.
Источники
Ответы (0)
Пока нет ответов в этой теме.