Webwright переводит управление браузером в терминал: модель генерирует и отлаживает Playwright‑скрипты, что даёт существенный прирост точности в задачах автоматизации, включая 60.1% на Odysseys с GPT‑5.4.
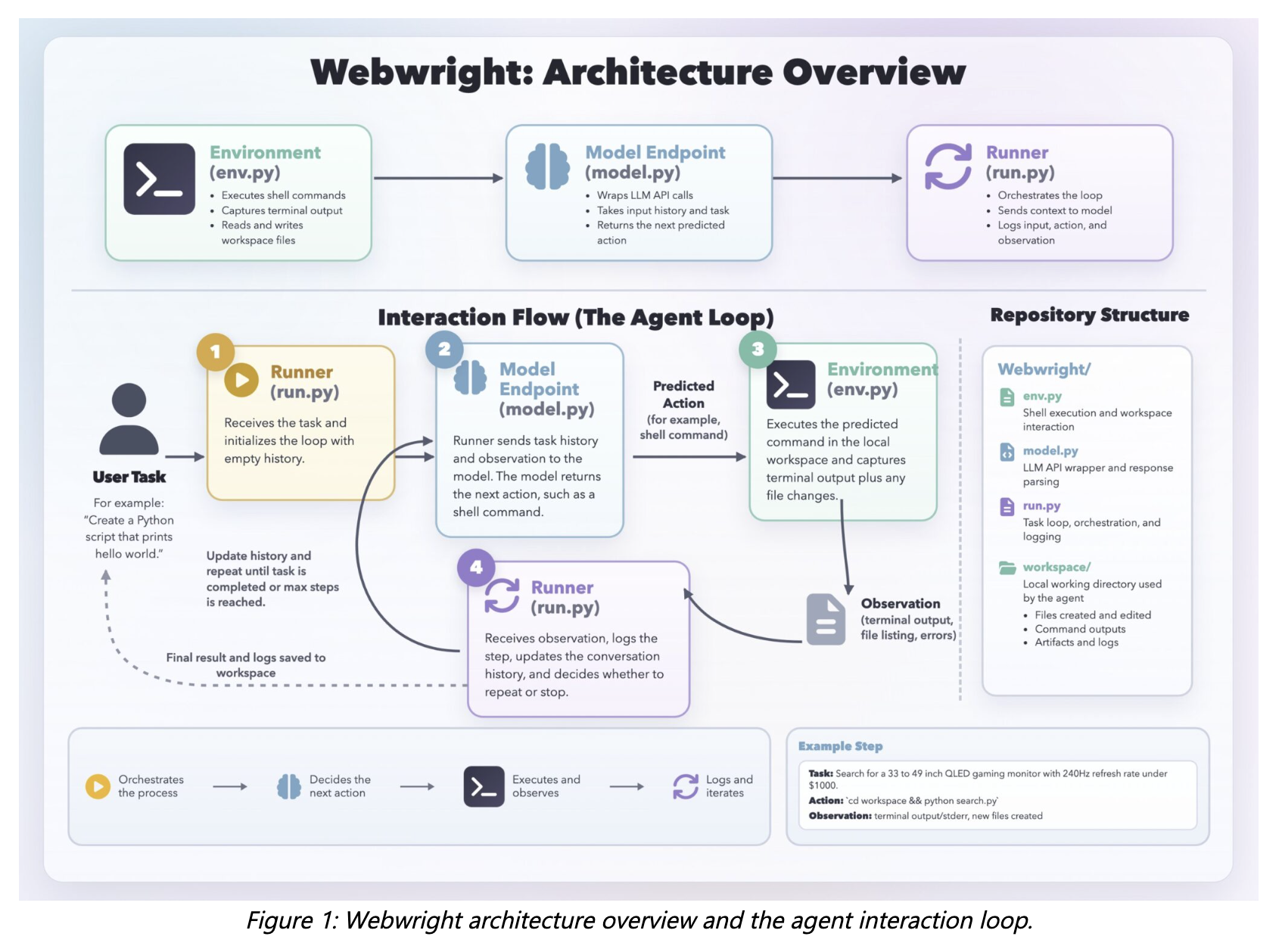
Microsoft Research представила Webwright — открытый терминальный фреймворк для веб‑агентов, в котором модель генерирует исполняемые Playwright‑скрипты, запускает их через shell, анализирует логи и итеративно дорабатывает код. Это меняет парадигму от покомандного управления браузером к созданию переносимых и отлаживаемых программных артефактов, что важно для повторяемости и промышленного применения автоматизации. Архитектура Webwright включает три модуля: Runner (≈150 строк кода), Model Endpoint (≈550 строк) и Environment (≈300 строк) — всего примерно 1 000 строк. Агент сохраняет все промежуточные артефакты — код, логи, скриншоты и результаты — в локальную рабочую папку, что упрощает инспекцию, отладку и повторный запуск сценариев. Сгенерированные скрипты управляют Chromium, Firefox и WebKit через Playwright.
Цикл работы агента организован как итеративная петля: Runner передаёт текущий контекст модели, модель отвечает блоком размышления и shell‑командой, среда выполняет команду и возвращает вывод терминала, логи, скриншоты или трассировки ошибок, затем наблюдения интегрируются в контекст и цикл повторяется. Такой формат позволяет выражать многокомандные взаимодействия как компактные программы с циклами, функциями и абстракциями, вместо предсказания отдельных кликов или нажатий.
Авторы отмечают две ключевые инженерные проблемы и их решения. Во‑первых, чтобы избежать преждевременного флага done, агент обязан сгенерировать self‑reflection конфиг и прогнать итоговый скрипт в чистой папке с логами и скриншотами; успешная самопроверка подтверждает завершение, иначе флаг сбрасывается и агент повторяет попытку. Во‑вторых, проблему роста контекста при длинных траекториях решают сжатием истории: каждые 20 шагов история агрегируется в сводный обзор.
Webwright протестировали на двух наборах задач: Online — Mind2Web (300 задач на 136 популярных сайтах) и Odysseys (long‑horizon). С GPT‑5.4 фреймворк показал 86.67% точности в AutoEval‑режиме Online — Mind2Web при бюджете 100 шагов — лучший результат среди опен‑сорс harness‑рецептов — и 60.1% на Odysseys. Для сравнения, базовая скриншот‑ориентированная версия GPT‑5.4, воспроизведённая авторами, показала 33.5%. одновременно подчёркнуты требования к управлению контекстом и надёжной самопроверке при интеграции терминального агента в продуктивные пайплайны.
Источники
Ответы (0)
Пока нет ответов в этой теме.