1 июня 2026 года MiniMax представила M3-open-weight модель с контекстным окном в миллион токенов, нативной мультимодальностью и механизмом MiniMax Sparse Attention; API уже доступно, веса обещаны «вскоре».
MiniMax официально выпустила модель M3 1 июня 2026 года — компания называет её первой открытой моделью, которая сочетает высокую производительность на кодовых задачах, родную обработку нескольких форматов данных и окно контекста в один миллион токенов. Это важно для команд разработки и исследователей: миллионный контекст позволяет сохранять и оперировать значительными объёмами состояния между сессиями и надёжно работать с большими многокомпонентными проектами. Ключевая техническая новация M3-механизм MiniMax Sparse Attention, который отбирает и обрабатывает только релевантные блоки внутри длинной последовательности. По заявлению разработчиков, такой подход сокращает вычислительную нагрузку примерно в 20 раз и ускоряет обработку входа более чем в 9 раз, что делает практичным миллионное окно контекста в реальных задачах.
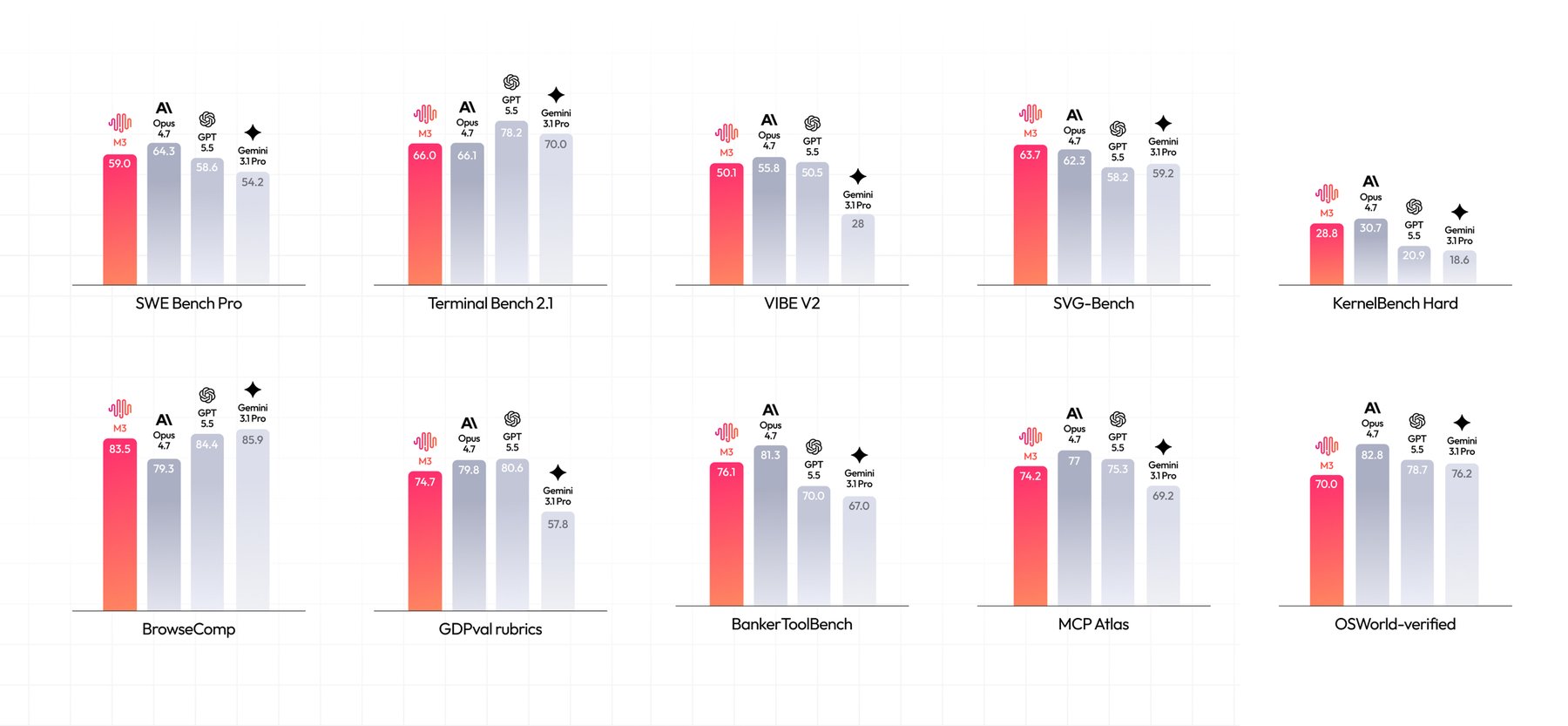
Для обучения M3 использовали «переплетённые» мультимодальные данные — текст и изображения в рамках одной последовательности — и симулятор рабочих потоков разработчиков для тренировки многоповоротного взаимодействия и поддержания контекста. Компания сообщает, что модель уже доступна через API, а веса будут опубликованы вскоре, что сделает M3 общедоступной для воспроизведения и доработки сообществом. Во внутренних бенчмарках MiniMax позиционирует M3 среди лидеров проприетарного класса. На SWE‑Bench Pro модель набирает 59% и, по заявлениям компании, опережает GPT‑5.5 и Gemini 3.1 Pro, оставаясь немного позади Opus 4.7. В автономном веб‑поиске по BrowseComp M3 показывает 83.5 балла против 79.3 у Opus 4.7. Компания также отмечает, что позднее Anthropic выпустила Opus 4.8, что повысило планку конкуренции.
Для демонстрации автономности MiniMax провела три экспериментальных сценария. В одном M3 почти 12 часов воспроизводила исследование по дообучению LLM, выполнила 18 коммитов, сгенерировала 23 фигуры и подтвердила ключевые выводы исходной работы (оценка 0.650). Во втором тесте модель примерно за ≈24 часа оптимизировала ядро умножения матриц под ускорители NVIDIA Hopper: загрузка аппаратуры выросла с 7.6% до 71.3%, а оптимальное решение было найдено примерно к 145 — 147‑й попытке. В тесте PostTrainBench M3 самостоятельно синтезировала данные и обучила четыре базовые модели — результаты уступают Opus 4.7 и GPT‑5.5, но заметно опережают большинство остальных участников.
Практические выводы для разработчиков очевидны: сочетание миллионного окна и Sparse Attention даёт новые возможности для долговременной отладки процессов, переноса состояния между сессиями и автоматической оптимизации пайплайнов. Пример с настройкой под Hopper иллюстрирует, что модель может проводить итеративные эксперименты по повышению эффективности железа и тем самым сокращать время на низкоуровневую оптимизацию. Вместе с тем большая часть результатов — внутренние тесты MiniMax; независимая верификация пока ограничена, и появление Opus 4.8 меняет конкурентный контекст.
Источники
Ответы (0)
Пока нет ответов в этой теме.