Mistral объявила о выпуске Voxtral — своей первой модели текст‑в‑речь, доступной одновременно в виде открытых весов и как коммерческое API. Компания заявляет, что цель релиза — закрыть «пробел выразительности», когда синтезированная речь остаётся разборчивой, но не передаёт стиль, ритм и эмоции оригинального говорящего. Voxtral сделан как гибридная система общей сложностью примерно 4 миллиарда параметров: основа‑декодер занимает около 3.4B, к ней добавлены 390M‑параметровый flow‑matching акустический трансформер и 300M‑параметровый нейрокодек. Такой состав должен сочетать способность поддерживать долгие последовательности с детальной генерацией акустики.
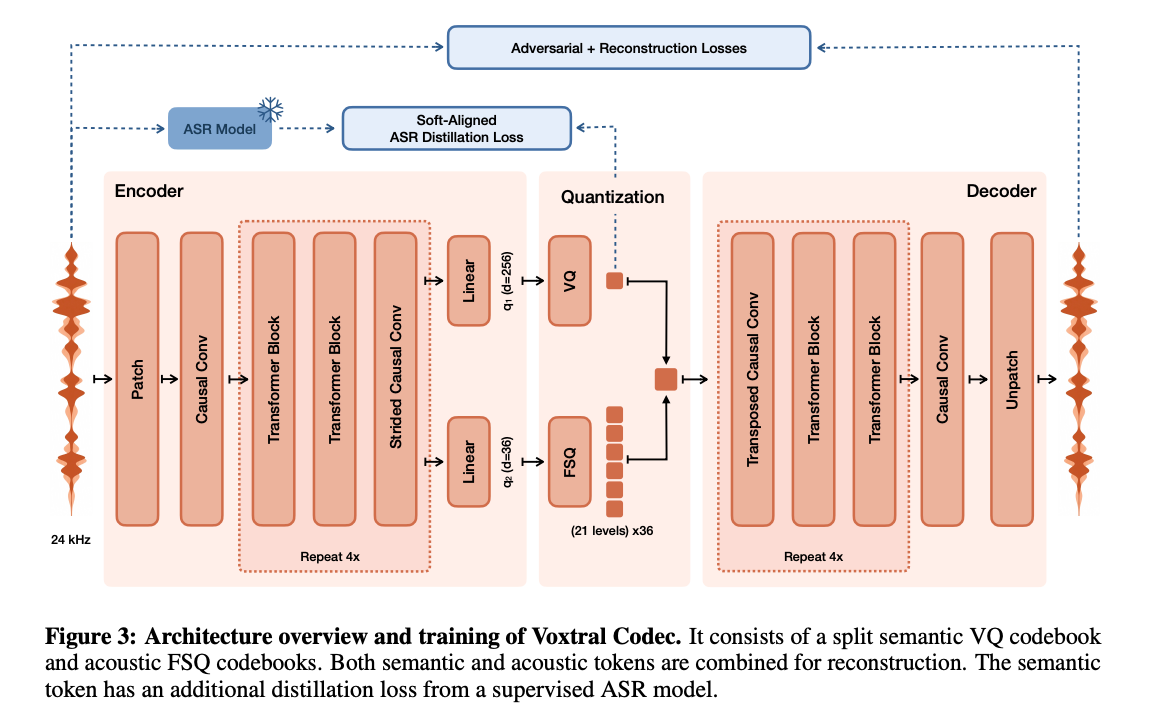
Ключевой компонент — Voxtral Codec, сверточно‑трансформерный автоэнкодер с гибридной VQ‑FSQ квантизацией. Он принимает моно‑сигнал с частотой 24 kHz и кодирует звук в кадровую последовательность с частотой 12.5 Hz (по одному кадру на 80 ms). Каждый кадр даёт 37 токенов: один семантический VQ‑токен (кодовая книга 8 192 записей) и 36 акустических FSQ‑токенов (по 21 уровню на измерение). Итоговый битрейт кодека — примерно 2.14 kbps; семантический токен тренируется через дистилляцию с использованием зафиксированной модели Whisper ASR.
За генерацию семантического потока отвечает авторегрессивный декодер, инициализированный из Ministral 3B: закодированные аудио‑токены ставятся в начало входной последовательности, затем модель по одному генерирует семантические токены на кадр до специального End‑of‑Audio токена, а линейная голова выдаёт логиты по 8 192 записям. Параллельно flow‑matching компонент синтезирует 36 акустических токенов, формируя богатую, непрерывную акустику и давая реалистичную текстуру звука.
Архитектурный выбор объясняется разделением задачи на уровень семантики (последовательность слов) и уровень акустики (индивидуальность голоса, просодия). По данным автора статьи, такое сочетание авторегрессии и flow‑matching обеспечивает лучшее соответствие долгой согласованности голоса и при этом гибкую акустическую вариативность. В экспериментах Voxtral Codec превосходит Mimi (кодек в Moshi) по Mel и STFT расстояниям, PESQ, ESTOI, WER ASR и сходству голоса на бенчмарке Expresso; в сравнительных оценках против ElevenLabs Flash v2.5 модель показывает 68.4% побед.
Практические характеристики делают систему применимой для сервисов в реальном времени: Voxtral генерирует естественную, похожую на донорский голос речь на девяти языках с эталонного фрагмента от примерно трёх секунд. По заявлению разработчиков, одна NVIDIA H200 способна обслуживать свыше 30 одновременных пользователей с задержкой ниже 600 мс. Одновременная публикация весов и API открывает возможность для исследований и интеграций, а заявленные метрики и производительность задают конкурентную планку для приложений — голосовых агентов, озвучки аудиокниг и многоязычной поддержки клиентов.
Источники
Ответы (0)
Пока нет ответов в этой теме.