Большая языковая модель OpenAI o1‑preview показала лучшие результаты, чем враачи, в ряде задач клинического рассуждения при анализе реальных записей отделений неотложной помощи — и это открытие, по мнению авторов, обосновывает дальнейшие контролируемые испытания с целью внедрения ИИ как инструмента «второго мнения». Результаты опубликованы 30 апреля в рецензируемой публикации и привлекли внимание как возможностью повышения качества поддержки принятия решений, так и рисками ошибочных прогнозов. В работе авторы сравнили выводы модели и клиницистов по набору диагностических и этапных задач, основанных на реальных записях работы скорой и приёмных отделений. Тестируемая версия — o1‑preview — уже была заменена более новыми релизами, но её показатели исследователи сочли достаточными для предложения дальнейшего тестирования LLM в реальных клинических условиях при строго контролируемых рабочих процессах.
публикации остаётся спорным: другие исследования дают противоречивые результаты. Некоторые работы отмечают впечатляющую диагностическую способность моделей, но ряд исследований фиксирует фабрикации ссылок, неверные рекомендации и сильную зависимость итогов от методик оценки. В одном из анализов почти половина ответов пяти популярных чат‑ботов на открытые медицинские вопросы оказалась ошибочной и сопровождалась вымышленными цитатами. Использование LLM в качестве поддержки принятия врачебных решений отличается от ответов на общие пользовательские запросы: у клиницистов больше контекстных знаний для обнаружения явных ошибок, однако это не устраняет проблему «галлюцинаций». По словам соавтора Adam Rodman, модели порой одинаково убедительны при верных и неверных ответах, что затрудняет их верификацию в клиническом потоке работ.

Разные исследовательские группы приходят к разным выводам в зависимости от критериев оценки. Так, 13 апреля в JAMA Network Arya Rao и коллеги протестировали 21 LLM в задачах клинического рассуждения и получили отличающиеся результаты; в других анализах сравнивали двух врачей и две LLM на этапах ухода в неотложке (работы Peter G. Brodeur, Thomas A. Buckley и соавторов), что подчёркивает вариативность выводов при различных методологиях.
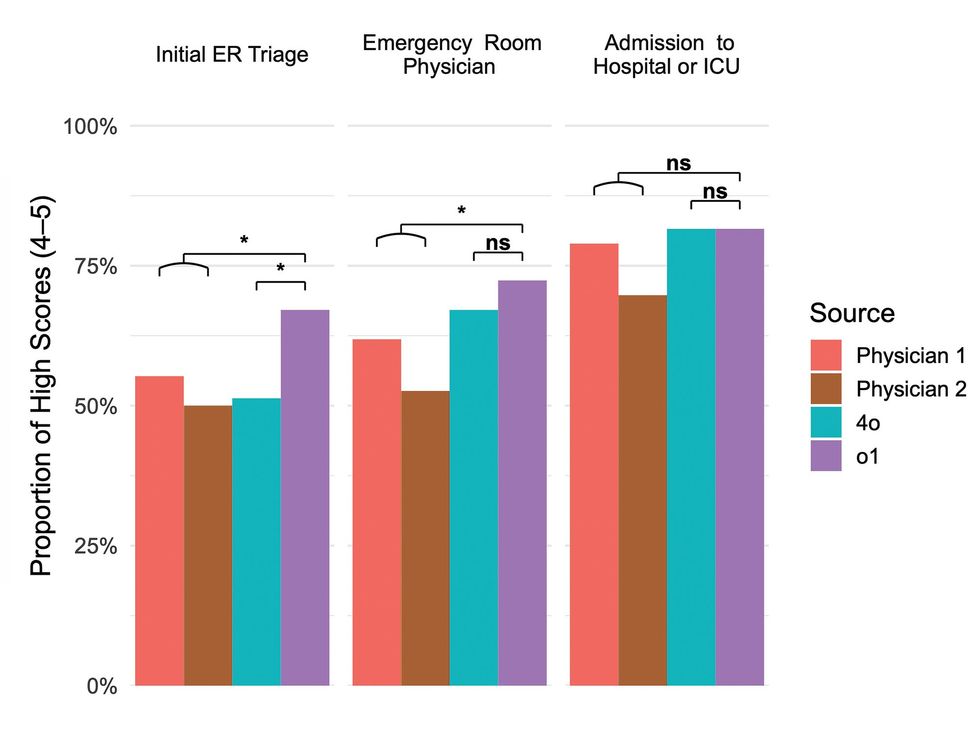
Авторы текущей статьи выражают осторожный оптимизм и одновременно подчёркивают ограничения исследования. Соавтор Arjun Manrai прямо заявил, что полученные данные не означают замены врачей, а Adam Rodman выразил обеспокоенность возможным неправильным использованием медицинских данных. Исследователи — в том числе Mickael Tordjman — призывают к проспективным клиническим испытаниям; для разработчиков это означает необходимость встроенных и проверяемых рабочих процессов, а также инструментов для обнаружения и предотвращения ошибок модельных прогнозов. В дополнение, в этом году OpenAI представила продукты, ориентированные на медиков: ChatGPT for Clinicians и ChatGPT for Healthcare, что делает вопрос интеграции LLM в клинику практически релевантным.
Источники
Ответы (0)
Пока нет ответов в этой теме.