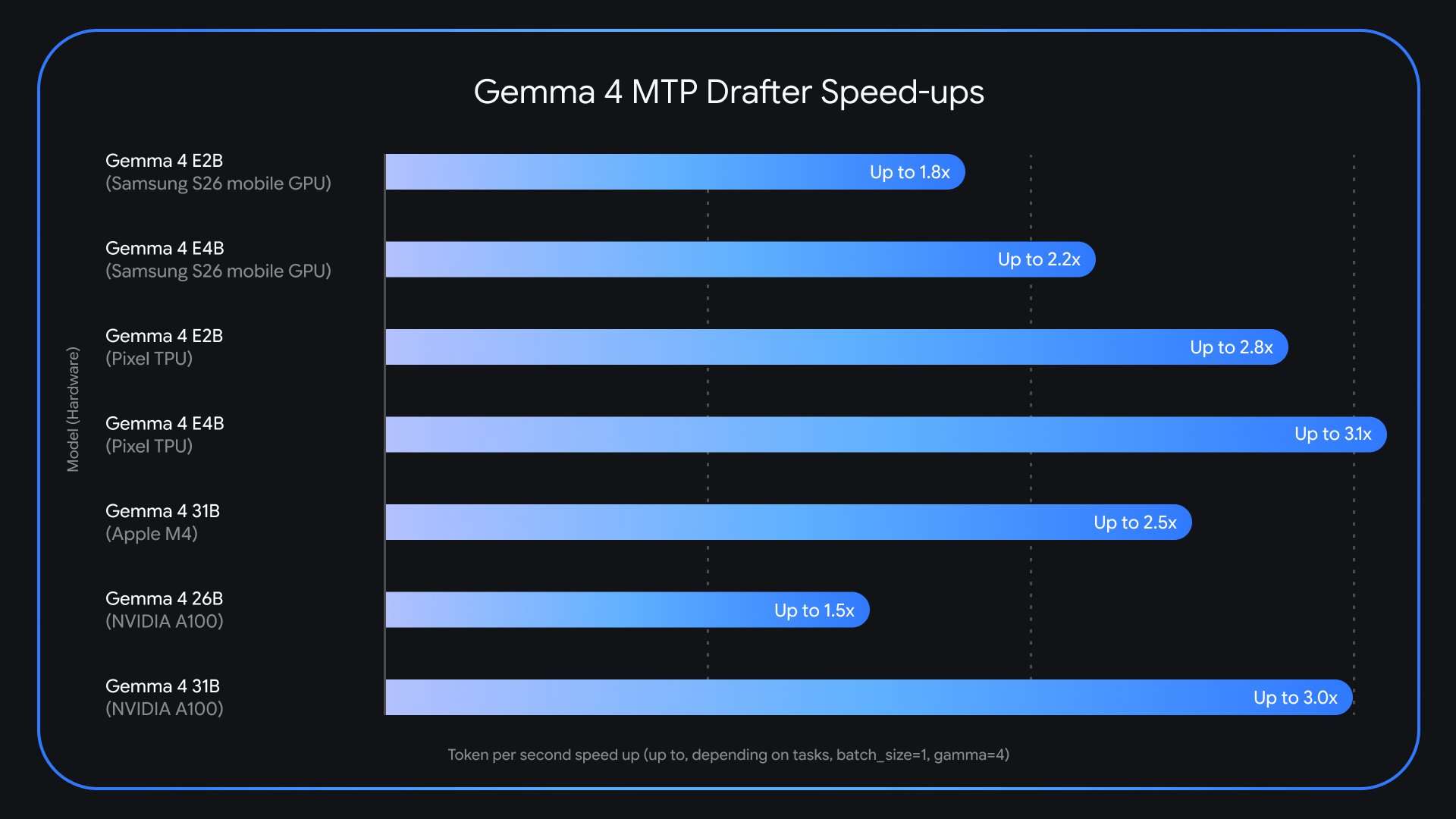
Анонсированы MTP (Multi‑Token Prediction) drafters для модели семейства Gemma 4 — специализированная реализация спекулятивного декодирования, которая, по заявлению разработчиков, позволяет ускорить генерацию выходного текста до трёх раз без ухудшения качества или точности рассуждений. Релиз появился всего через несколько недель после того, как Gemma 4 превысила 60 млн загрузок. Проблема, которую решают MTP drafters, связана с характером современный больших языковых моделей: они работают авторегрессивно и последовательно генерируют ровно по одному токену. Для каждого шага приходится загружать миллиарды параметров модели из видеопамяти (VRAM) в вычислительные блоки, и именно скорость передачи данных между памятью и вычислением становится узким местом — а не сырая вычислительная мощность GPU или процессора.
Из‑за этого вычислительные ресурсы часто простаивают, пока система занята перемещением параметров, что даёт заметную задержку при инференсе. Более того, стандартный авторегрессивный подход не различает «лёгкие» и «трудные» предсказания: на тривиально предсказуемые токены, например завершение общеизвестных фраз, тратится столько же вычислений, сколько на сложные логические выводы. MTP drafters опираются на технику спекулятивного декодирования — подход, который позволяет предсказывать несколько токенов вперёд и таким образом уменьшить число обращений к полной модели на каждом шаге. В результате снижается нагрузка на пропускную способность памяти: часть последовательности формируется спекулятивно и затем подтверждается или откатывается при необходимости, что экономит время и пропускную способность.
По задумке, этот метод напрямую адресует узкое место памяти и пропускной способности при генерации токенов независимо от доступного аппаратного ускорения, то есть выигрыш во времени достигается не только через более мощные GPU, но и через более эффективную организацию обмена данными. Разработчики подчёркивают, что при этом сохраняется качество вывода и точность рассуждений модели. Внедрение MTP drafters может облегчить развертывание больших языковых моделей в задачах с жёсткими требованиями по задержке и пропускной способности, поскольку сокращает периоды простоя вычислений и уменьшает общие временные затраты на генерацию текста. Подробности и технические объяснения представлены в исходном сообщении разработчиков.
Источники
Ответы (0)
Пока нет ответов в этой теме.