Nous Research предложила Contrastive Neuron Attribution (CNA) — метод, который находит разреженные «цепочки» MLP‑нейронов, отвечающие за отказ от вредных инструкций, и проверяет причинность их абляцией на инференсе.
Nous Research представила Contrastive Neuron Attribution (CNA) — метод локализации и управления разреженными MLP‑нейронными «цепочками», которые реализуют поведение отказа от выполнения вредных инструкций. Исследователи показывают, что достаточно аблатировать небольшую долю таких нейронов во время инференса, чтобы резко уменьшить число отказов, при этом не изменяя весов модели и не проводя дополнительного обучения. Это важно, потому что позволяет управлять поведением уже выровненных (instruct) моделей без дорогостоящих процедур дообучения.
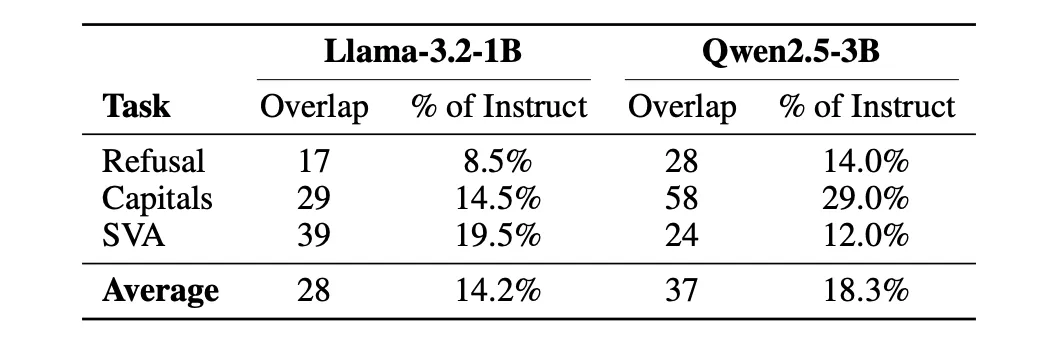
Метод формирует контрастные наборы промптов — позитивные (вредные запросы) и негативные (безопасные) — и для каждого MLP‑слоя фиксирует down‑projection активацию в позиции последнего токена. Для каждого нейрона вычисляется средняя разница δ между наборами, после чего выбираются top‑k нейронов по абсолютной δ (исходная настройка k = 0.1% от всех MLP‑активаций). Нейроны, которые оказываются в топ‑0.1% для ≥80% промптов, считаются «универсальными» и фильтруются. Причинность проверяется масштабированием активации каждого нейрона множителем m (m=0 — полная абляция, m=1 — базовая, m>1 — усиление).
Авторы противопоставляют CNA существующим подходам: Contrastive Activation Addition (CAA) оперирует усреднённой разницей в residual‑потоке и применяет вектор управления по всей ширине слоя, что даёт «грубый» эффект и при сильном управлении снижает качество вывода; sparse autoencoders (SAE) требуют внешнего дорогостоящего обучения и чувствительны к шуму. CNA, в отличие от них, не требует градиентов, вспомогательного обучения или итеративного поиска — достаточно прямых прогонов. структура, разграничивающая вредные и безвредные промпты, уже существует в базовых моделях, а alignment‑fine‑tuning лишь перестраивает функцию нейронов внутри этой структуры, формируя разреженный «затвор отказа», который CNA может найти и модифицировать.
Эксперименты охватили 16 моделей — базовые и instruct‑варианты Llama 3.1/3.2 и Qwen 2.5 с параметрами от 1B до 72B; основной бенчмарк — JBB — Behaviors (NeurIPS 2024), набор из 100 вредных промптов. Для обнаружения отказной «цепочки» использовались по 100 вредных и 100 безопасных промптов; для качественных иллюстраций и некоторых задач авторы применяли по 8 положительных и 8 отрицательных примеров.
По результатам абляция порядка 0.1% MLP‑активаций сократила долю отказов более чем на 50% в большинстве instruct‑моделей, при этом метрика качества вывода (1 − доля повторяющихся n‑грамм) оставалась выше 0.97 при всех уровнях управления. В отдельных результатах: Llama‑3.1 70B‑Instruct — с 86% отказов до 18% (−79.1%); Qwen2.5 7B‑Instruct — с 87% до 2% (−97.7%); Qwen2.5 72B‑Instruct — с 78% до 8% (−89.7%). Не во всех случаях снижение превышало 50%: Llama‑3.2 3B и Qwen2.5 3B показали более скромные относительные падения.
Авторы также отмечают слабости CAA: при максимальных силах управления её показатели по метрике качества опускались ниже 0.60 в шести из восьми instruct‑моделей, а в отдельных случаях (Qwen2.5‑1.5B и Qwen2.5‑72B) приводили к серьёзной деградации вывода, что подчёркивает преимущество целевой, разреженной абляции CNA.
Источники
Ответы (0)
Пока нет ответов в этой теме.