Nous Research описала метод селекционной иерархической агрегации, который на предобучении моделей с контекстом 98K токенов даёт 1.40–1.
Nous Research представила тренировочный механизм селекционной иерархической агрегации, который сокращает время предобучения длинноконтекстных трансформеров на 1.40–1.69× по wall‑clock в сравнении с cuDNN‑базовой scaled dot‑product attention (SDPA) при сопоставимом или меньшем финальном значении функции потерь. Это обеспечивает реальную экономию времени при больших контекстах, причём селекция применяется только в предобучении и затем убирается, оставляя модель плотной для продакшен‑инференса.
Авторы проверили подход на модели в стиле Llama‑3 с 530M параметров и контекстом 98K токенов; измеряемая экономия времени отражает end‑to‑end ускорение обучения по сравнению со стандартным SDPA. Метод формулирует эффективность «вызова внимания» как переход вычислений для соответствующей части от O(N·S·d) к O(S²·d) и затем запускает оптимизированный FlashAttention на компактной, непрерывной подсеквенции, что даёт практический выигрыш времени.
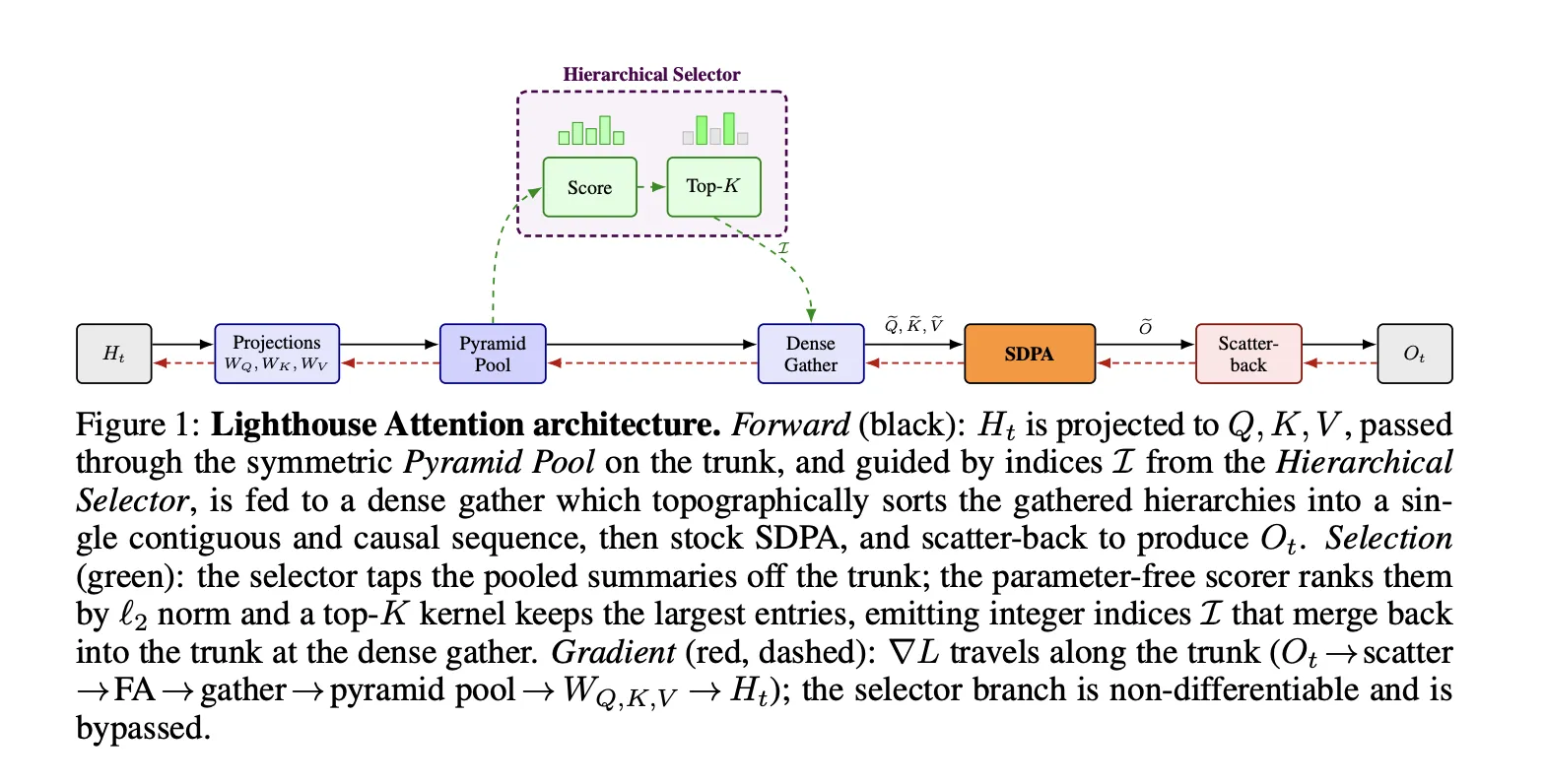
Технически слой состоит из четырёх стадий. Сначала для Q, K и V строится L‑уровневая пирамида через average‑pooling; построение пирамиды занимает Θ(N) по времени и памяти. Затем параметр‑фри скорер на основе per‑head L2‑норм присваивает каждой ячейке два скалярных балла, причём более грубые уровни наследуют значения через max‑pooling. Далее chunked‑bitonic ядро выполняет стратифицированный top‑K, причём самый грубый уровень всегда сохраняется; отбор дискретен и недифференцируем — индексы отбора не несут градиента, а градиенты текут через выбранные Q, K, V в параметры WQ, WK и WV.
Подход целенаправленно выносит логику селекции за пределы ядра attention, в отличие от методов, которые сжимают только K/V и встраивают выбор в кастомное attention‑ядро (NSA, HISA, DSA, MoBA). Это позволяет переиспользовать оптимизированные плотные GPU‑ядра (например, FlashAttention), решая задачу обучения: после удаления селектора полученные веса остаются компетентны для плотного SDPA на инференсе. Для реализации важны симметричный пулинг Q/K/V, сохранение самого грубого уровня для покрытия всех позиций, стратифицированный top‑K чтобы избежать «коллапса» селекции на узком диапазоне и линейная стоимость построения пирамиды. Исходные материалы и подробности реализации доступны в препринте и примерах кода (см. источники).
Источники
Ответы (0)
Пока нет ответов в этой теме.