Nous Research представила Token Superposition Training (TST), двухфазный протокол предобучения больших языковых моделей, который при сопоставимых FLOPs снижает реальное (wall‑clock) время тренировки до примерно 2,5×. Метод не меняет архитектуру модели, токенайзер, оптимизатор, стратегию распараллеливания или поведение при инференсе; по завершении Phase 2 модель имеет привычную голову для next‑token предсказания. Для инженеров это означает возможность увеличить объём обрабатываемого текста на FLOP без вмешательства в инференс‑строку и токенизацию.
В Phase 1 (Superposition) входная последовательность длины L разбивается на неперекрывающиеся «мешки» по s последовательных токенов; эмбеддинги токенов мешка усредняются в один s‑токен, и трансформер обрабатывает последовательности укороченной длины L/s. Чтобы сохранять шаг равным по FLOPs стандартному шагу, в фазе суперпозиции увеличивают объём обрабатываемого текста в s раз. На уровне обучения каждая позиция предсказывает следующий мешок из s токенов с использованием multi‑hot cross‑entropy (MCE), которая сводится к среднему стандартных CE‑термов и реализуема через существующие fused CE‑ядра.
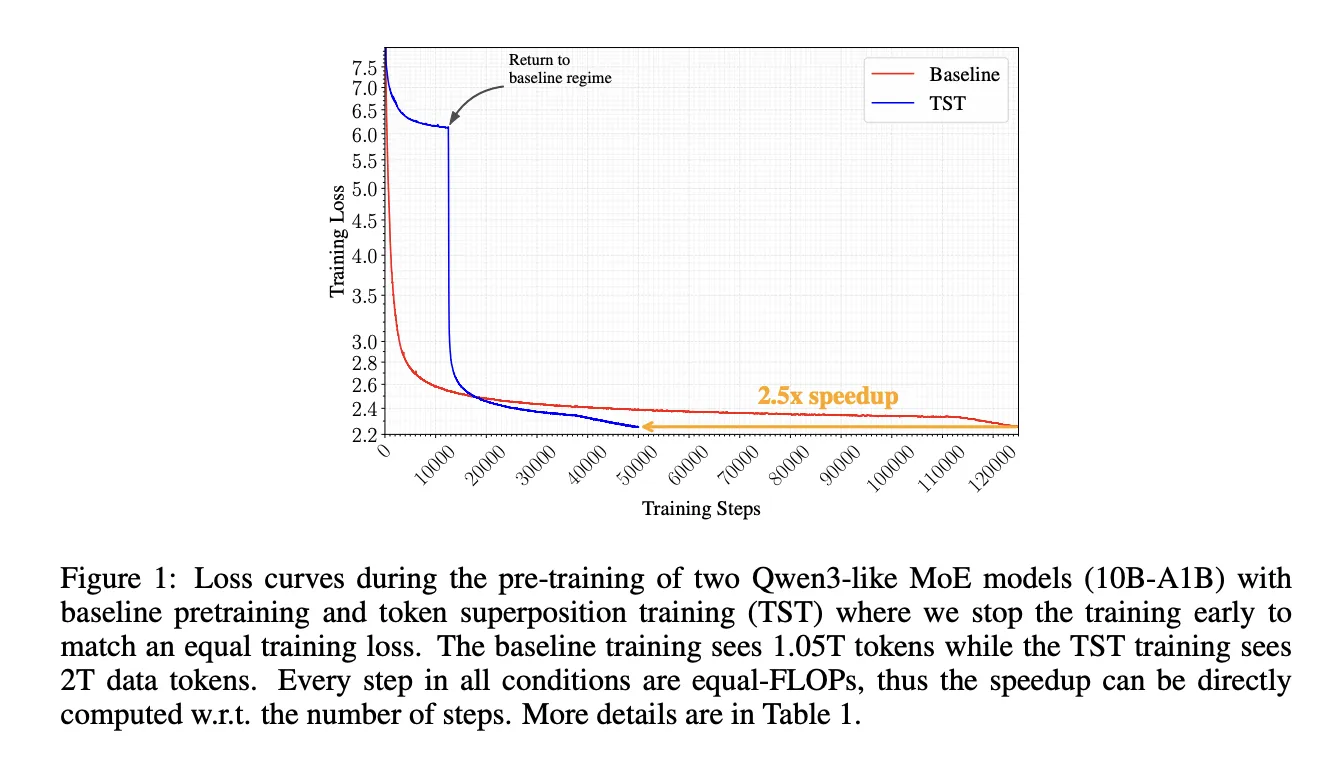
После заранее заданной доли шагов r (авторы указывают r ∈ [0.2, 0.4] как близкое к оптимальному) наступает Phase 2 (Recovery): обучение возобновляют с сохранённого чекпоинта и переходят на обычную задачу next‑token для оставшихся 1−r шагов. При переходе наблюдается переходный всплеск loss примерно на 1–2 nats; этот spike стабилизируется за несколько тысяч шагов, после чего восстановленная модель опускается ниже контрольного baseline при равных FLOPs.
TST проверяли на четырёх масштабах: 270M и 600M dense (формы SmolLM2, адаптированные к коду Llama3), 3B dense (SmolLM3‑shape) и 10B A1B MoE (семейство Qwen3). Меньшие прогонки использовали датасет DCLM; MoE‑прогон — 50/50 смесь DCLM и FineWeb‑Edu. Все эксперименты шли с оптимизатором AdamW и расписанием Warmup‑Stable‑Decay в реализации TorchTitan под FSDP, на оборудовании NVIDIA B200 (8 B200 для малых запусков, 64 B200 для больших).
По числовым результатам: для 10B A1B MoE TST достигла более низкого финального training loss при затраченных ~4,768 B200 GPU‑часах против 12,311 у равного‑FLOPs baseline — что соответствует примерно 2.5× экономии wall‑clock времени. В конфигурации 3B с s=6 и r=0.3 к 20,000 шагам зафиксирован финальный loss 2.676, которую авторы приводят как иллюстрацию выгод TST.
Практические выводы для инженерных команд: TST повышает объём текста, обрабатываемого на единицу FLOP, не требует изменений токенайзера или инференс‑головы, а MCE реализуется через существующие fused CE‑ядра, поэтому не нужен отдельный kernel или дополнительная голова. В то же время рабочий поток требует сохранения чекпоинта и перехода между фазами, а ожидаемый переходный spike loss следует учитывать при планировании расписаний обучения и валидаций.
Источники
Ответы (0)
Пока нет ответов в этой теме.