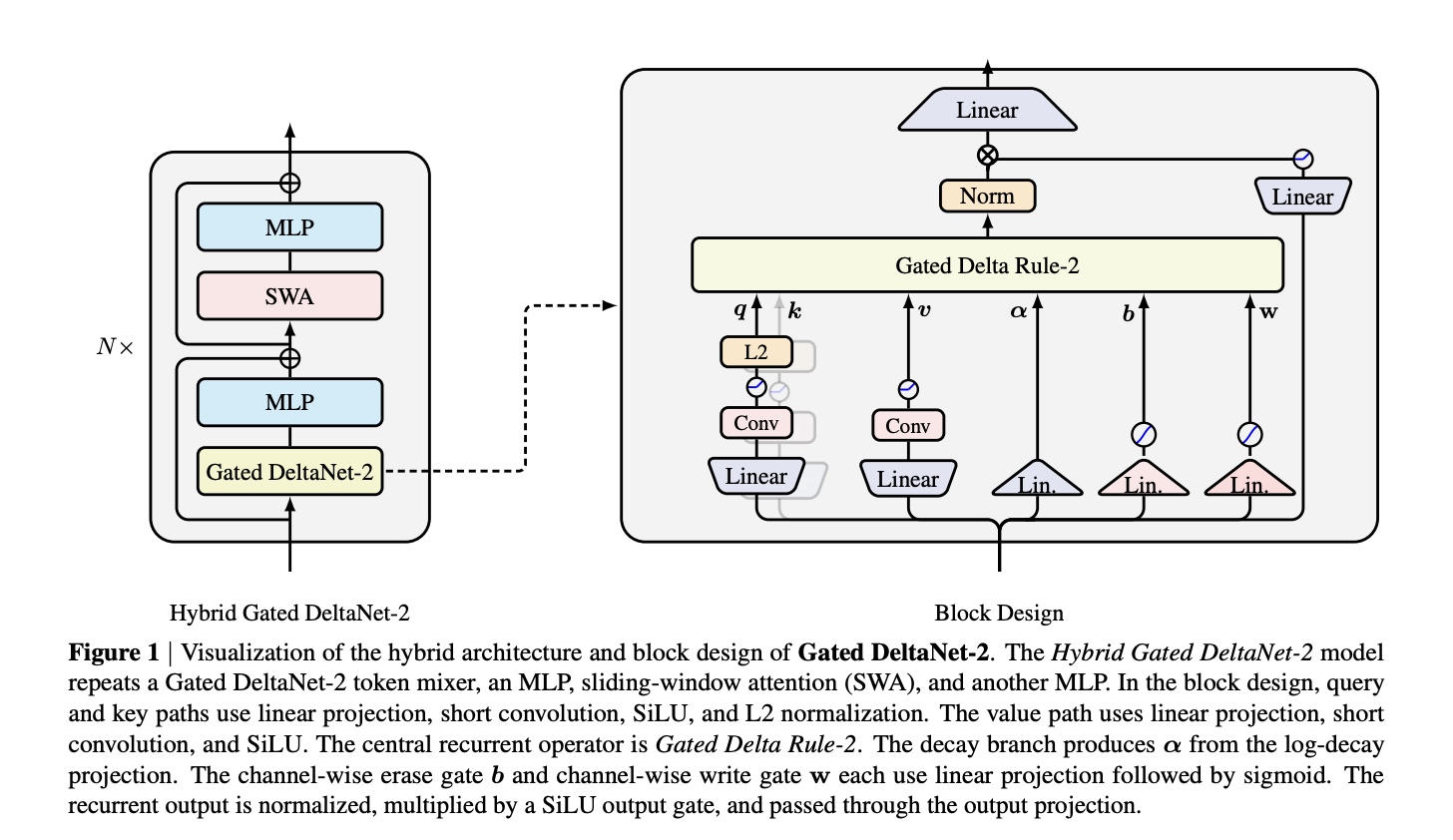
NVIDIA выпустила Gated DeltaNet‑2 — новый линейный слой внимания, который разделяет управление стиранием и записью в дельта‑правиле через канал‑wise гейты, что делает обновления сжатой KV‑памяти более избирательными и стабильными. Это напрямую решает ограничение традиционных дельта‑правил: раньше единый скаляр одновременно управлял и стиранием, и записью, теперь эти операции декомпозированы по каналам, что важно для надёжного редактирования внутреннего состояния при сохранении линейной сложности по длине последовательности.
Техническая схема вводит два канал‑wise гейта: вектор стирания b_t ∈ [0,1]^{d_k} по оси ключей и вектор записи w_t ∈ [0,1]^{d_v} по оси значений; оба получают через сигмоида‑проекции токенных представлений. Обновление состояния записано так: S_t = (I − k_t (b_t ⊙ k_t)ᵀ) D_t S_{t−1} + k_t (w_t ⊙ v_t)ᵀ, где D_t = Diag(α_t) — канал‑wise decay. В реализации запись и стирание применяются до и после затухания соответственно, что меняет порядок и избирательность модификаций состояния по каналам.
Реализация поддерживает chunkwise WY‑форму с размером чанка C = 64 и использует объединённые Triton‑ядра: аккумулируемая канал‑wise затухающая компонента поглощается в ранговых факторах (rank‑1). Для обратного прохода привычный скалярный шорткат KDA неприменим: градиенты требуют явного учёта разных диагональных гейтов. Авторы вывели gate‑aware vector — Якобиан‑произведения для корректного вычисления градиентов и ограничили fused WY backward‑ядро на Hopper GPU двумя и четырьмя warps во избежание assertion в WGMMA‑layout.
Архитектурно Gated DeltaNet‑2 встроен как рекуррентный токен‑миксер в блоки типа Transformer. Пути query/key используют линейные проекции, короткие causal‑свертки, SiLU и L2‑нормализацию; путь value — линейную проекцию, короткую свёртку и SiLU; выход рекуррентного слоя проходит RMS‑нормализацию. При сведении гейтов в один скаляр модель восстанавливает KDA или Gated DeltaNet, то есть прежние подходы оказываются частными случаями нового обобщения.
В экспериментах Gated DeltaNet‑2 на модели с 1.3B параметров, обученной на 100B FineWeb‑Edu токенах, превосходит Mamba‑2, Gated DeltaNet, KDA и Mamba‑3 по набору бенчмарков: языковое моделирование, задачи commonsense‑рассуждений и retrieval по длинному контексту. Наибольшие улучшения отмечены на RULER S — NIAH и в multi‑key needle задачах. Для инженеров это означает более стабильное редактирование сжатой памяти при сохранении линейной сложности по последовательности и постоянного использования памяти при декодировании.
Источники
Ответы (0)
Пока нет ответов в этой теме.