NVIDIA представила семейство языковых моделей Nemotron‑Labs‑Diffusion, которое объединяет три режима декодирования — autoregressive (AR), diffusion и self‑speculation — в одной нейросети. Модели выпускались в трёх размерах (3B, 8B, 14B параметров) и доступны в вариантах base, instruct и vision‑language, что делает их пригодными как для чисто языковых, так и для мультимодальных задач. Это объединение режимов в одной сети важно потому, что позволяет гибко адаптировать режим генерации под нагрузку и требование к задержке, не меняя инфраструктуру модели.
Архитектура использует одни и те же веса для всех трёх режимов. AR‑режим — это стандартный слева‑направо causal‑decode. Diffusion‑режим организует последовательность в фиксированные блоки: внутри блока действует двунаправленное внимание, между блоками — каузальное, а обучаемый сэмплер предсказывает, какие позиции можно «зафиксировать» на шаге денойзинга. Self‑speculation сочетает параллельное черновое создание и последовательную верификацию, предлагая компромисс между скоростью и качеством вывода.
Весь цикл работы выполняется в одной и той же модели без вспомогательных драфтовых голов. Для обучения авторы комбинируют две потери: L(θ) = L_AR(θ) + α·L_diff(θ), где коэффициент α выбран равным 0.3 на основании аблаций. Процесс обучения проходил в два этапа: сначала чисто AR‑предобучение на одном триллионе токенов, затем совместная цель на дополнительных 300 миллиардах токенов. Модели инициализировались от предобученных Ministral3‑base.
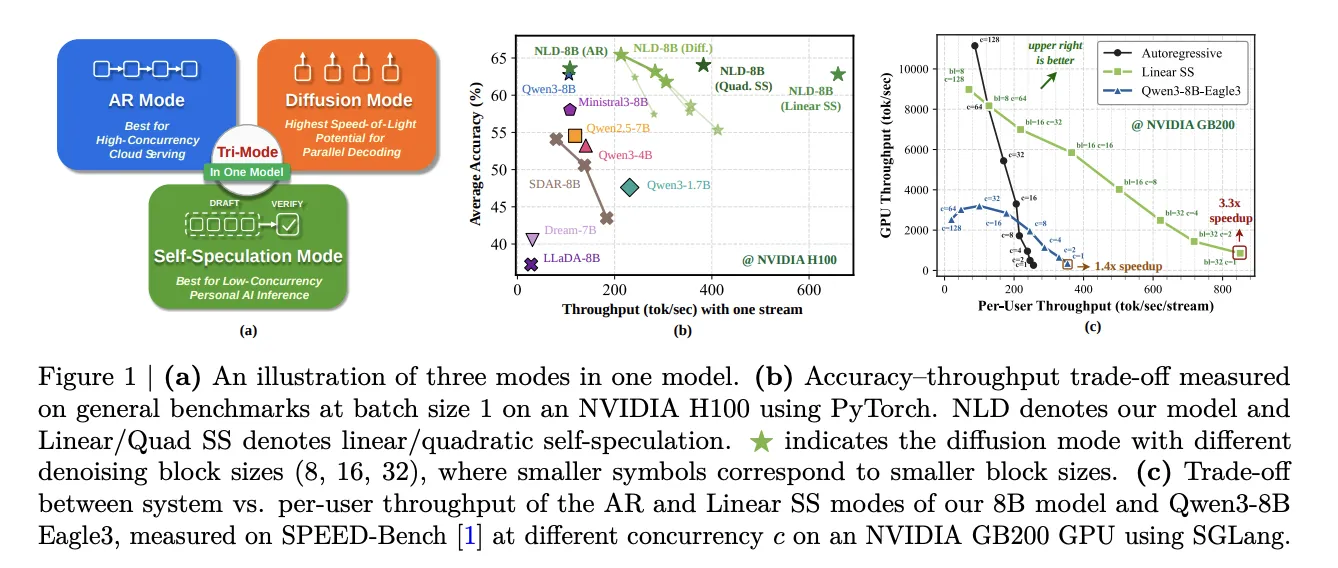
Авторы подчёркивают проблему классических AR‑моделей при низких батчах и единичных пользователях — низкую загрузку GPU и ограниченный throughput. Diffusion‑подход позволяет денойзить сразу несколько токенов за один forward, повышая количество генерируемых токенов на проход; в отчёте приводится сравнение, где Nemotron демонстрирует до 6× токенов на forward по сравнению с Qwen3‑8B. Self‑speculation авторы противопоставляют подходам Multi‑Token Prediction (например, Eagle3), где задействуют вспомогательные драфтовые головы.
С практической точки зрения, одна и та же модель теперь может переключаться между режимами без архитектурных модификаций или отдельного драфт‑моделя. Авторы рекомендуют AR‑режим для высококонкурентной облачной подачи, diffusion‑режим — для повышения пропускной способности при параллельной генерации блоков, а self‑speculation — как способ сочетать параллельное черновое создание и последовательную проверку, что может улучшать использование KV‑кэша и эффективность при низких батчах. Технический отчёт, опубликованный авторами, содержит подробности методики: описание сэмплера, результаты аблаций и настройку α, длительности этапов обучения и вклад отдельных компонентов. В документе приведены численные эффекты отдельных решений: +5.74% от двухэтапного обучения, +7.48% от добавления AR‑потери и суммарное улучшение средней точности на +16.05%.
Источники
Ответы (0)
Пока нет ответов в этой теме.