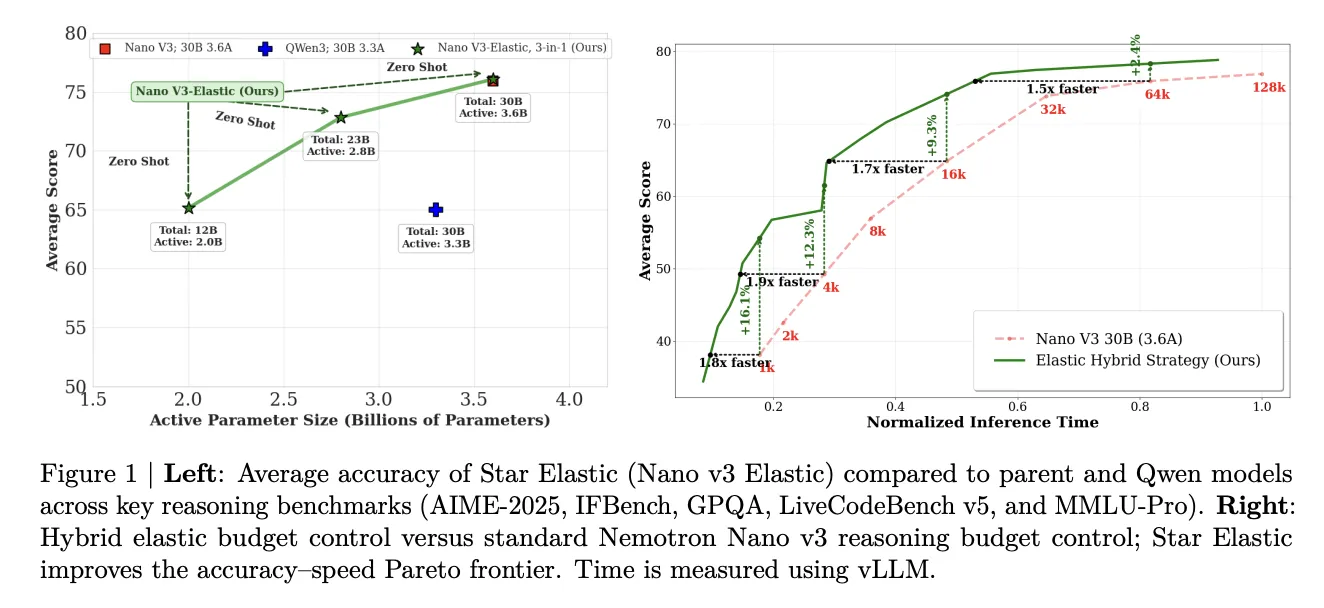
Star Elastic — посттренировочная схема, которая помещает три вложенные рассуждающие модели (30B, 23B и 12B параметров) в один чекпоинт и позволяет извлекать их без дополнительного дообучения, экономя хранение и вычисления.
NVIDIA показала Star Elastic — метод, который объединяет три варианта модели с 30B, 23B и 12B параметров в одном чекпоинте и позволяет переключаться между ними без повторного файн‑тюнинга. Это достигается после единого обучения примерно на 160 млрд токенов; главное практическое значение — упрощение хранения и возможность снижать ресурсы при выводе, используя более лёгкую версию для рассуждений и полную модель для финального ответа.
Подход реализован на базе Nemotron Elastic и был продемонстрирован на Nemotron Nano v3 — гибридной архитектуре Mamba (Transformer — MoE) с 30 млрд параметров и 3.6 млрд активных параметров. Star Elastic порождает вложенные версии 23B (2.8B активных) и 12B (2.0B активных), при этом все три варианта сосуществуют в одном файле весов и извлекаются без дополнительного обучения.
Ключевая идея — ранжировать блоки по их вкладу в точность (эмбеддинги, attention‑главы, Mamba SSM‑головы, MoE‑эксперты и FFN‑каналы) и для меньших подмоделей использовать наиболее значимые непрерывные подмножества весов. Такая селекция позволяет сохранить концентрированную полезную информацию в компактных вариантах модели вместо простого жёсткого обрезания параметров. Технически Star Elastic применяет обучаемый роутер, который получает целевой бюджет (one‑hot) и формирует дифференцируемые маски через Gumbel‑Softmax; для MoE‑слоёв использован алгоритм REAP (Router — Weighted Expert Activation Pruning), ранжирующий экспертов по значимости их выходов и весам роутинга. В отличие от статичных схем сжатия (например, Minitron), архитектуры вложений здесь определяются совместно с обучением модели.
Демонстрация на Nemotron Nano v3 показывает применимость идеи, но её масштабирование и влияние на другие архитектуры потребуют дополнительной валидации.
Источники
Ответы (0)
Пока нет ответов в этой теме.