Исследователи NVIDIA представили Polar — прокси‑фреймворк, который вставляет модель‑прокси между агент‑harness и сервером вывода, фиксирует взаимодействия на уровне токенов и восстанавливает траектории для обучения (включая GRPO) без изменения кода harness;
NVIDIA представила Polar — инфраструктуру‑прокси для обучения с подкреплением, которая позволяет использовать существующие агент‑harness (Codex CLI, Claude Code, Qwen Code и т. п.) без правки их кода, сохраняя полную токенную информацию взаимодействий. Это важно потому, что Polar обеспечивает нативную точность данных исполнения и позволяет восстановить обучающие траектории для алгоритмов вроде GRPO, не меняя логики harness. В результате команды могут подключать существующие агенты к тренировочному пайплайну быстрее и с меньшими изменениями в инфраструктуре.
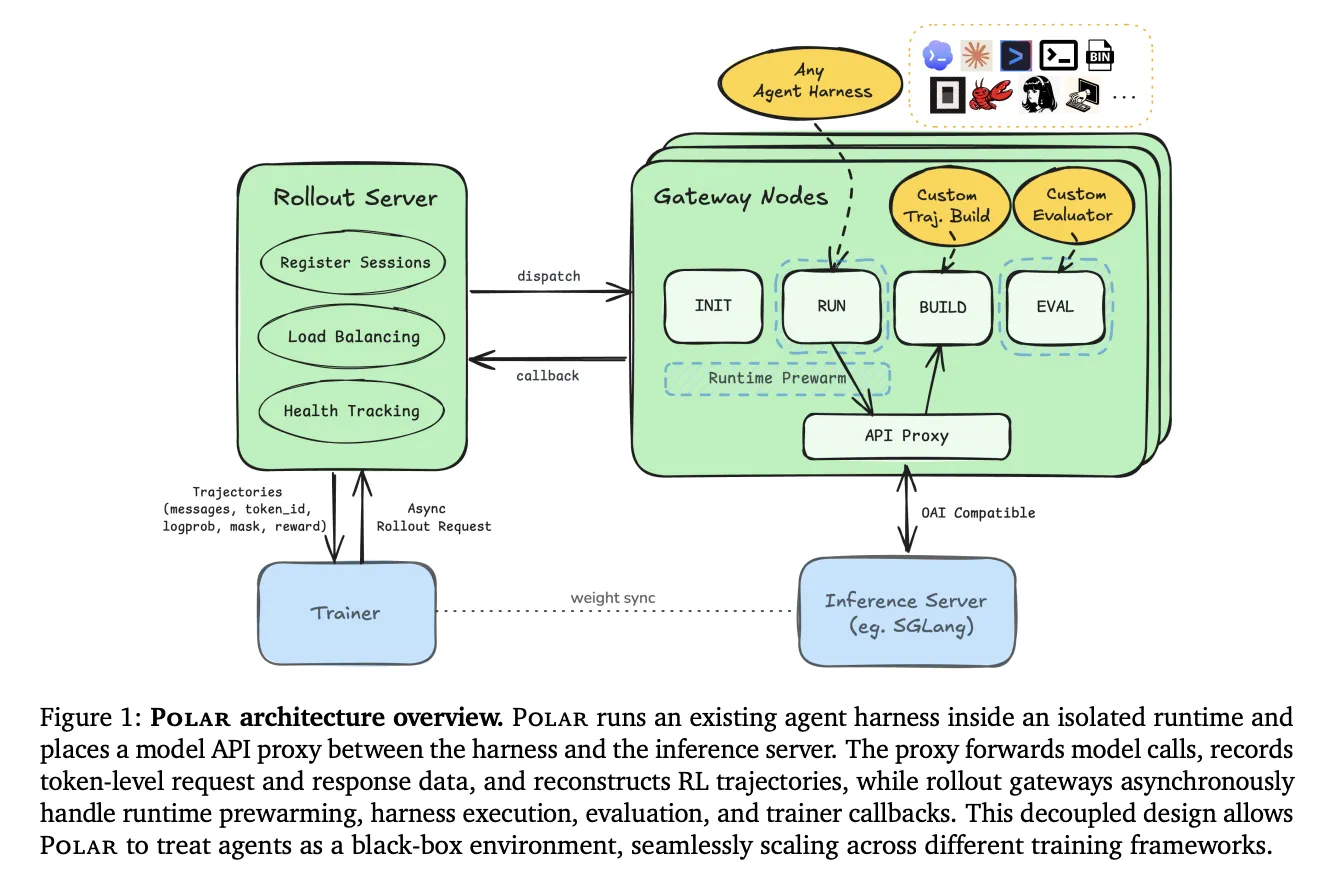
Polar действует как прозрачный шлюз на границе вызова модели: прокси обрабатывает каждое обращение в четыре шага. Сначала он определяет провайдера по пути и заголовкам (поддерживаются форматы Anthropic Messages, OpenAI Chat Completions/Responses и Google generateContent‑style). Затем запрос нормализуется в форму OpenAI Chat Completions, после чего прокси захватывает данные на уровне токенов — запросные и ответные сообщения, ID токенов подсказки, сэмплированные ID ответных токенов, finish reason и log‑probabilities — и в конце возвращает ответ в форме, ожидаемой harness.
Единственное требуемое изменение в существующем harness — перенастроить базовый URL модели на gateway Polar. Архитектура разделена на rollout‑сервер и gateway‑ноды: rollout‑сервер принимает TaskRequest и разворачивает num_samples сессий, каждая из которых хранит session_id, task_id, timeout‑budget, runtime‑ и agent‑спецификации, builder траекторий, evaluator и callback URL; затем сервер диспетчирует сессии на gateway‑ноды для выполнения. Gateway управляет жизненным циклом рантайма и сбором траекторий: он запускает runtime, выполняет harness, собирает токенные данные, оценивает результат и проводит teardown. Внутри gateway изолированные пулы воркеров обслуживают стадии INIT, RUNNING и POSTRUN, а буфер READY ограничивает очередь подготовленных рантаймов, что упрощает параллельное исполнение и управление ресурсами.
Polar восстанавливает обучающие траектории двумя стратегиями. Первая, per_request, рассматривает каждый вызов модели как независимый трейс — это безпотерьно для одиночных вызовов, но фрагментирует многоходовые сессии. В документе также описан подход prefix‑merging; выбор билдера влияет на сохранение контекста при построении траекторий для RL‑алгоритмов вроде GRPO. В экспериментах с GRPO на базе Qwen3.5-4B Polar продемонстрировал заметный прирост: SWE‑Bench Verified pass@1 вырос на 22.6 пункта под harness Codex, на 4.8 пункта под Claude Code и на 6.2 пункта под Pi.
Практическая совместимость Polar включает поддержку Docker и rootless Apptainer рантаймов, а также встроенные сокращения для harness: codex, claude_code, gemini_cli, qwen_code, opencode и pi. Фреймворк зарегистрирован как NeMo Gym environment и опубликован в репозитории ProRL Agent Server, что упрощает воспроизводимость и интеграцию для исследователей и команд разработки; инженеры при этом могут подключать существующий агент к тренировочному пайплайну без переписывания логики harness, сохраняя нативные детали исполнения и полную токенную информацию для обучения.
Источники
Ответы (0)
Пока нет ответов в этой теме.