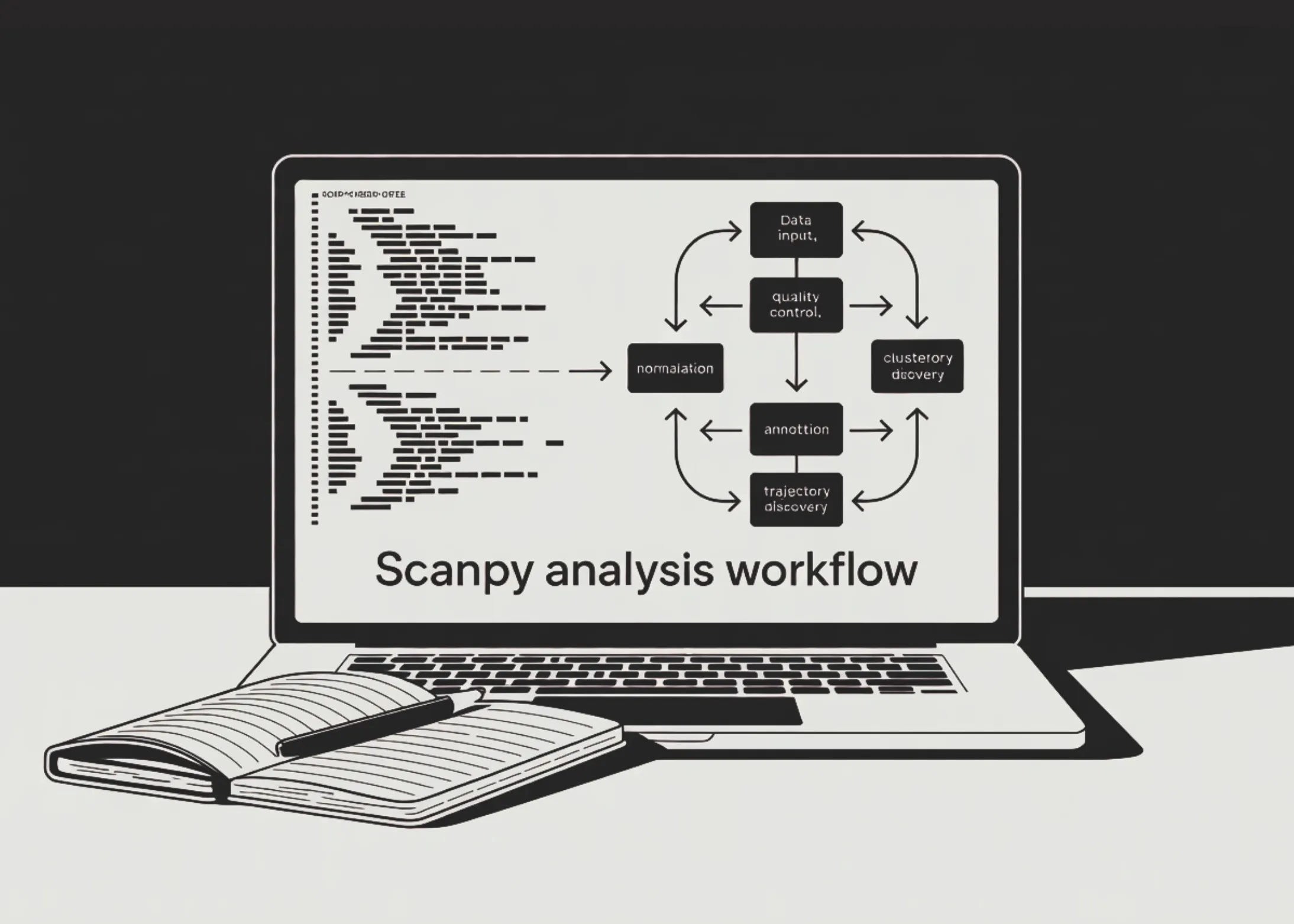
Опубликован практический workflow для анализа single‑cell RNA‑seq на базе Scanpy, выполненный на эталонном датасете PBMC‑3k: авторы демонстрируют полный конвейер от первичной загрузки до сохранения проанализированного объекта AnnData, что упрощает воспроизводимость и последующее использование результатов. В начале показан импорт и упаковка данных в объект AnnData, проверка структуры и расчёт метрик качества: число генов, суммарные счёты, доля митохондриальных и рибосомных счётов. Эти метрики вычисляются до фильтрации и служат основой для принятия решений о порогах качества при очистке клеток и генов.
Туториал приводит конкретные команды и код для настройки окружения и работы: рекомендуемая установка pip install -q scanpy leidenalg python — igraph scrublet; импорт библиотек scanpy, numpy, pandas, matplotlib и конфигурация sc.settings; загрузка данных sc.datasets.pbmc3k(); пометка генов mt и ribo; вызов sc.pp.calculate_qc_metrics; визуализации violin и scatter. Показаны фильтры sc.pp.filter_cells(min_genes=200) и sc.pp.filter_genes(min_cells=3), а также обнаружение даблетов через Scrublet.
Далее описаны шаги нормализации и предобработки: сохранение raw, нормализация, логарифмирование (log1p) и отбор высоковариабельных генов. Для удаления технической вариации выполняются регрессия и масштабирование, после чего применяются методы снижения размерности — PCA, UMAP и t‑SNE — и кластеризация алгоритмом Leiden. В руководстве показаны подходы к поиску маркерных генов и аннотации популяций по каноническим маркерам PBMC. Для изучения динамики и траекторий используются PAGA и diffusion pseudotime; также демонстрируется расчёт пользовательского interferon‑response score. В финале показано сохранение полностью проанализированного объекта AnnData для последующего анализа, что делает конвейер удобным для исследований кластеров, маркеров и траекторий на PBMC‑3k.
Источники
Ответы (0)
Пока нет ответов в этой теме.