Группа исследователей из Northwestern University, Tilde Research и University of Washington представила Parallax — параметризованный вариант Local Linear Attention (LLA), который не заменяет softmax‑внимание, а дополняет его вычислительной ветвью для коррекции ковариации. Это решение сохраняет привычную семантику softmax‑веса и одновременно даёт путь для учёта ковариационных членов, что важно для того, чтобы интегрировать улучшения внимания в существующие пайплайны предобучения больших языковых моделей и в код‑базу Muon.
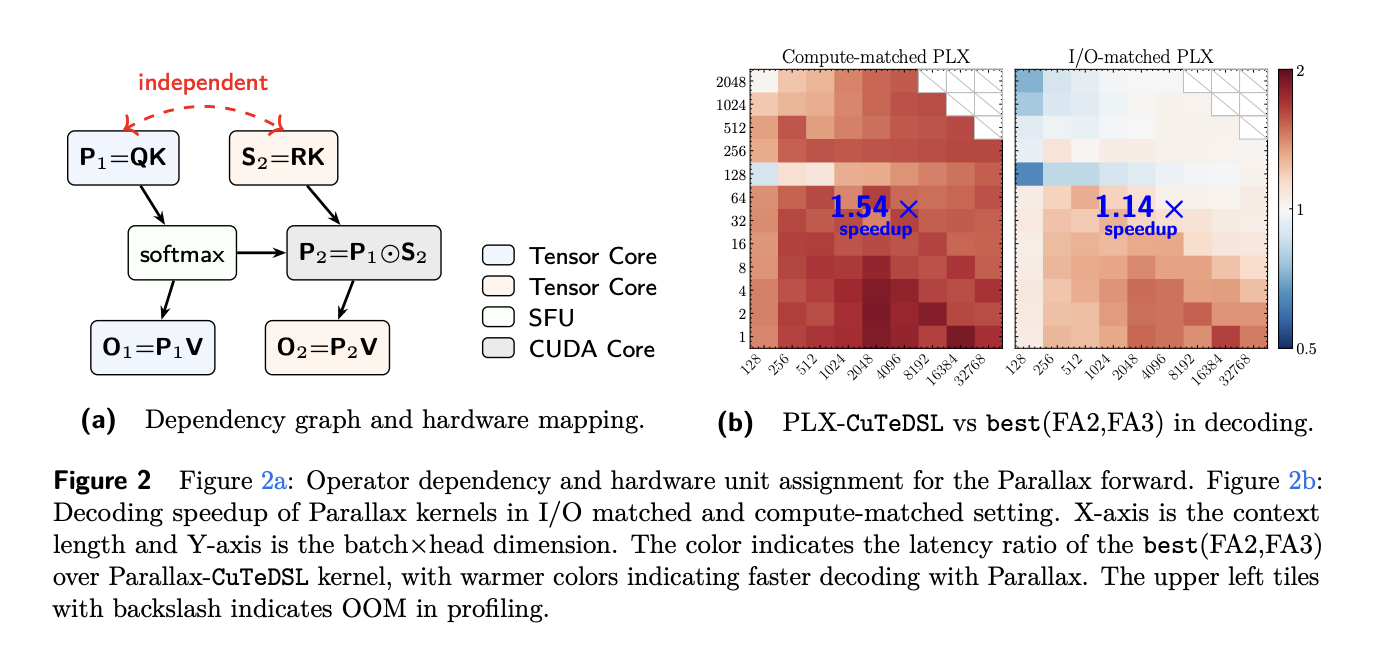
Технически Parallax устраняет требование решать для каждого запроса систему линейных уравнений, присущее LLA, и заменяет её обучаемой проекцией ρi = WR xi, где WR-обучаемая матрица, пробующая ковариацию ключ‑значение напрямую из входа слоя. В выводе это выражается как стандартный softmax‑выход минус проекционный ковариационный член. Авторы также отключают фактор усиления на границе (boundary amplification), установив его в ноль ради численной устойчивости в параметрической постановке. С аппаратно‑реализационной точки зрения Parallax сохраняет потоковую структуру FlashAttention: новая ветвь ковариации повторно использует те же потоки K и V. Прямой проход развёрнут в две параллельные шкалирующие ветви, которые разделяют онлайн‑максимум, фактор перерасчёта и тайлы K/V, поэтому паритет ввода‑вывода остаётся неизменным, а добавленная вычислительная работа повышает арифметическую интенсивность реализации.
Авторы аргументируют выигрышом производительности за счёт сдвига в compute‑bound режим: при доминирующей работе с KV Parallax примерно удваивает отношение операций к трафику памяти, что делает оптимизацию кернелов более эффективной на современных тензорных ядрах. В качестве прототипа они реализовали decode‑кернел в CuTeDSL на архитектуре NVIDIA Hopper и профилировали его против FlashAttention 2 и 3 на H200 в BF16, проведя сканирование по batch‑size (1 — 2048) и длине контекста (128 — 32 768).
Для разработчиков и инженеров ключевое преимущество в том, что Parallax сохраняет геометрию LLA (локальную линейность) без дорогостоящего per‑query CG‑решателя, устраняя связанные с ним проблемы — высокие требования к I/O, жёсткий компромисс между регуляризацией и выразительностью и несовместимость с низкой точностью. При WR = 0 слой вырождается в обычное softmax‑внимание, поэтому конвертация предобученных чекпоинтов возможна путём добавления WR и дообучения — практичная дорожная карта для поэтапного внедрения в существующие системы.
Источники
Ответы (0)
Пока нет ответов в этой теме.