Платформа объявила встроенное кэширование префиксов (prompt caching) для открытых моделей — автоматически повторно использует KV‑кэши одинаковых префиксов, доступно для batch‑инференса, опции pay‑per‑token и provisioned‑throughput;
Платформа внедрила встроенное кэширование префиксов (prompt caching) для открытых моделей, что позволяет автоматически повторно использовать KV‑кэши одинаковых системных и инструкционных префиксов и сокращать этап prefill при инференсе. Это ускоряет генерацию и снижает издержки при массовой обработке запросов и чат‑сценариях — особенно в батч‑пайплайнах и при рабочей нагрузке с оплатой по токенам или выделенной пропускной способностью. Короткое значение для бизнеса: инженерам и архитекторам не требуется менять клиентский код, чтобы получить выигрыш в throughput и latency.
Механизм работает прозрачно: система обнаруживает повторяющиеся префиксы промптов и автоматически повторно использует соответствующие KV‑буферы без ручной конфигурации. При попадании префикса в кэш стадия предзаполнения токенов пропускается, и модель продолжает генерацию с уже готовыми KV‑кешами, что экономит повторные вычисления для одинаковых или близких префиксов. Кэширование распространяется на базовые модели, подключённые через Foundation Model API, включая GPT‑OSS 20B и GPT‑OSS 120B, Gemma 3 12B, Llama 3.1 8B (включая варианты, дообученные через PEFT‑serving) и Llama 3.3 70B. Кроме того, механизм применяется и на более высоких сервисах, построенных на FM API-например, в Agent Bricks, Genie и AI Functions, где повторяющиеся системные инструкции встречаются часто.
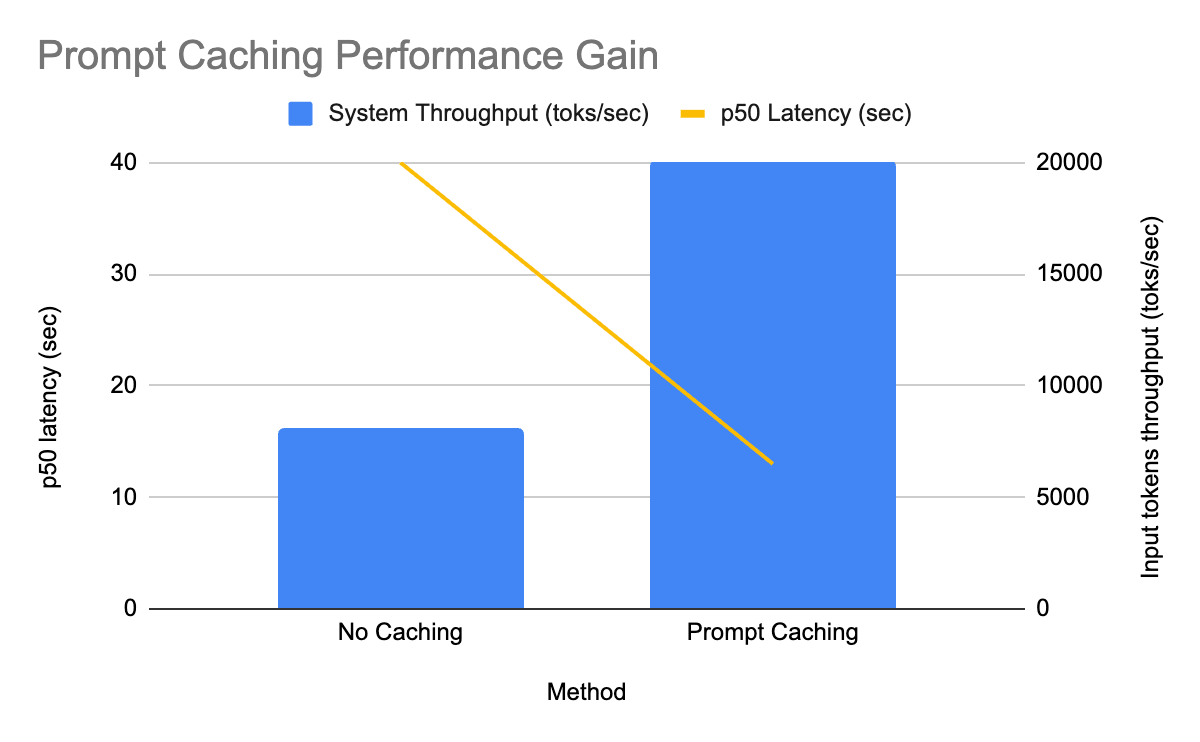
Технически ключевая экономия достигается за счёт устранения повторного прохода по идентичным системным или инструкционным префиксам: при кеш‑хите этап prefill не выполняется, модель использует предварительно заполненные KV‑буферы для продолжения генерации. Это особенно важно при тысячах схожих запросов и при длинных системных промптах, которые у frontier‑моделей могут достигать тысяч токенов, — кэш амортизирует их стоимость. Реальные измерения показали существенный эффект: при развёртывании на GPT‑OSS в крупном production batch‑pipeline платформа зафиксировала рост входного throughput на реплику в 2.5× и сокращение медианной (P50) латентности в 3×. Эти улучшения были получены при относительно невысоком hit‑rate кэша — около 30%, что подчёркивает эффективность подхода даже при частичных совпадениях префиксов.
Практические последствия и рекомендации: кэширование помогает ускорять чат‑сервисы в реальном времени, массовую обработку документов и агентные сценарии без доработок приложения. Кэши изолированы и хранятся только в volatile памяти — они не персистируются на диск. Компания планирует расширять покрытие функции на дополнительные модели и рекомендует мониторить hit‑rate для оценки потенциальной экономии. в задачах с высокой уникальностью промптов выигрыш будет меньше, поэтому перед развёртыванием стоит протестировать показатели throughput и latency на вашем наборе данных.
Источники
Ответы (0)
Пока нет ответов в этой теме.