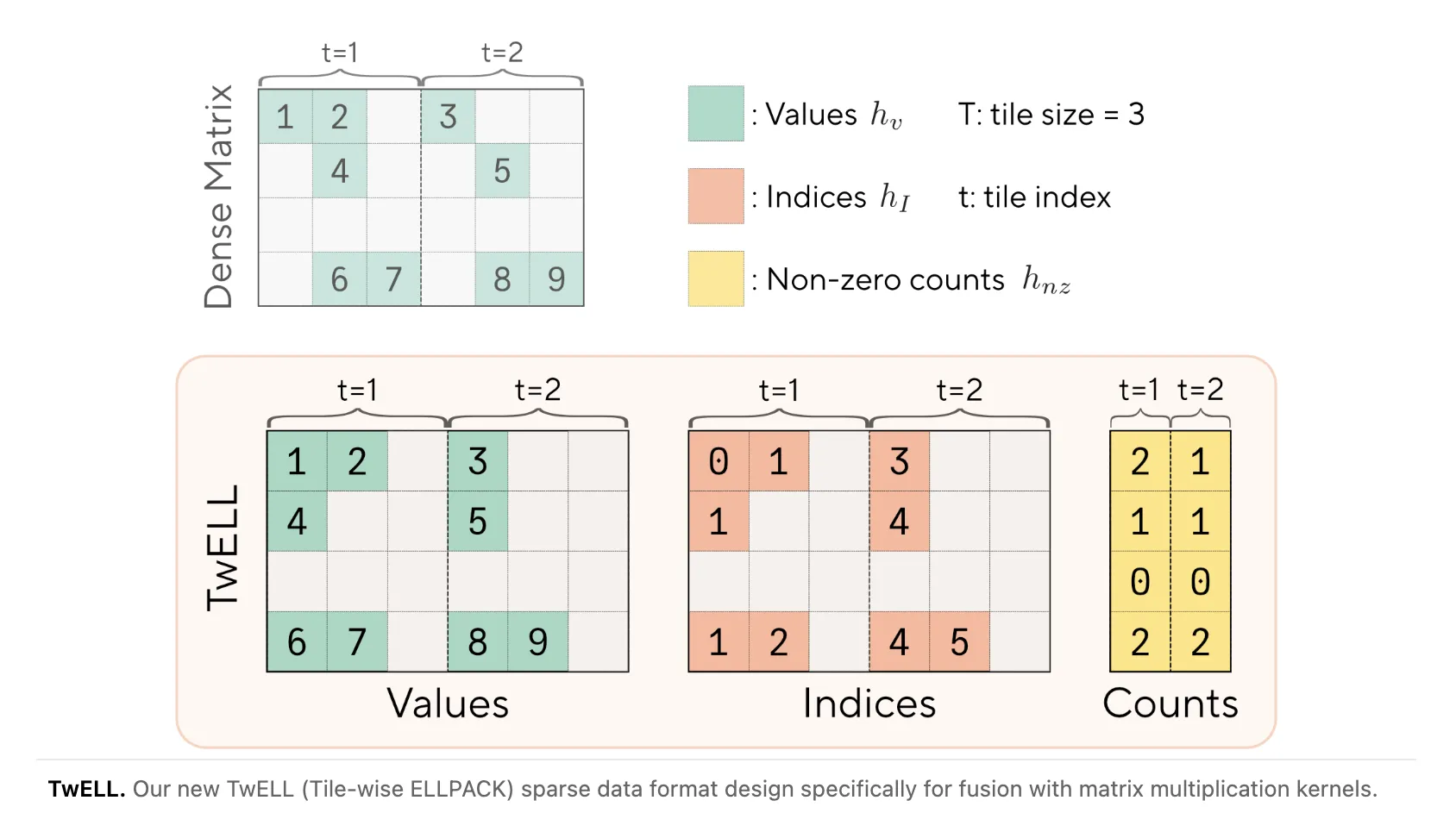
Sakana AI и исследователи NVIDIA представили формат данных TwELL и набор специализированных CUDA‑ядер, которые позволяют превратить активную разреженность активаций в значимое ускорение больших трансформеров — это важно, потому что feedforward (вторичные) блоки доминируют в вычислениях и параметрах моделей и потому являются узким местом для масштабирования LLM в батчевых сценариях. Авторы отмечают, что вторичные (feedforward) блоки составляют более двух третей параметров модели и генерируют свыше 80% FLOPs. Они также показали, что простая L1‑регуляризация на активациях индуцирует более 99% нулевых значений в скрытых нейронах без заметного падения качества, что делает эти блоки естественным кандидатом для разрежённых представлений.
TwELL разбивает матрицы по горизонтальным плиткам, согласованным с размером плитки матричного умножения T_n, и упаковывает ненулевые элементы локально внутри каждой плитки. Формат формируется непосредственно в эпилоге ядра проекции «gate», что устраняет отдельный проход конвертации, лишние обращения к глобальной памяти и синхронизацию между этапами. Для инференса разработано объединённое (fused) CUDA‑ядро, которое читает активации в формате TwELL и сразу выполняет «up» и «down» проекции, не записывая промежуточное скрытое состояние в глобальную память; это заметно снижает DRAM‑трафик на каждый прямой проход. Для обучения предложен гибридный формат, который динамически маршрутизирует строки либо в компактную ELL‑матрицу (разрежённые строки), либо в плотный бэкап для переполнений.
Ранее существовавшие подходы к разрежённым ядрам (TurboSparse, ProSparse, Q‑Sparse и другие) были нацелены на режим GEMV с одним‑несколькими токенами и узкопамятные операции и не масштабировались до батчевой, вычислительно‑ограниченной среды GEMM с тысячами токенов, где плотные реализации на Tensor Cores обеспечивают порядок‑размерно большую пропускную способность. TwELL специально адресует этот более жёсткий режим и ориентирован на совместную работу с широкими батчами. В экспериментах сочетание TwELL‑формата и специализированных CUDA‑ядер дало реальные приросты пропускной способности: +20.5% для инференса и +21.9% для обучения по сравнению с плотными базовыми реализациями. Авторы подчёркивают, что выигрыш достигается без изменения архитектуры модели, но требует внедрения новых ядер и форматов данных в вычислительные пайплайны.
Практическое значение для команд, работающих с LLM: подход сокращает DRAM‑трафик и уменьшает вычислительную нагрузку на feedforward‑блоки в батчевых сценариях, однако при обучении нужно учитывать неравномерность разреженности — максимальное число ненулевых элементов на строку может значительно превышать среднее. Командам рекомендовано тестировать TwELL на их размерах батчей и формах матриц и интегрировать поддержку формата в CUDA‑ядра, чтобы получить заявленные выигрыши.
Источники
Ответы (0)
Пока нет ответов в этой теме.