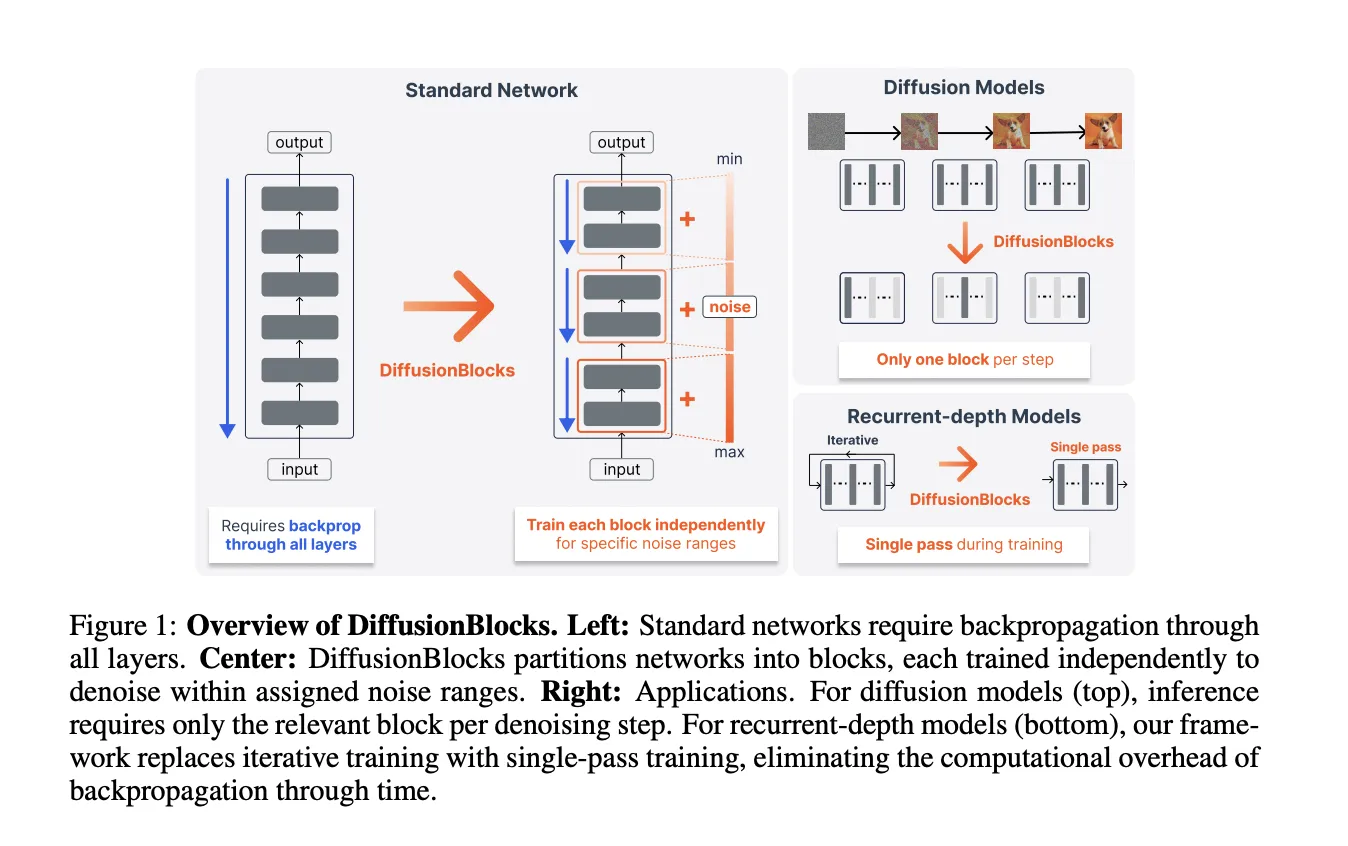
Исследователи из Sakana AI и Университета Токио предложили DiffusionBlocks — блок‑овый фреймворк, который преобразует стек residual‑блоков в последовательность независимо обучаемых шагов денойзинга. Метод описан в докладе на arXiv (2506.14202) и важен тем, что позволяет снизить пиковую память при обучении глубоких моделей, что даёт инженерам возможность обучать более глубокие сети или увеличивать размер батча на том же оборудовании.
Ключевая техническая идея — увидеть residual‑обновления как дискретизацию обратного процесса в score‑based диффузии. В варианте Variance Exploding (VE) обратный процесс задаётся уравнением d z_σ / d σ = −σ ∇_z log p_σ(z_σ). Дискретизация этого уравнения приводит к обновлению той же формы, что и z_l = z_{l−1} + f_{θ_l}(z_{l−1}), поэтому стек residual‑блоков естественно интерпретируется как последовательность шагов денойзинга по интервалу шумов [σ_min, σ_max].
Для превращения существующей сети в DiffusionBlocks авторы предлагают три изменения: (1) разбить L слоёв на B блоков, где каждый блок — это последовательность слоёв; (2) задать распределение шума p_noise и разбить интервал [σ_min, σ_max] на B интервалов (рекомендуется log‑normal для p_noise); (3) ввести conditioning по уровню шума и подать в ввод блока зашумлённую версию цели, реализовав conditioning, например, через AdaLN, чтобы блок учился предсказывать чистую цель из зашумлённой в своём диапазоне шумов.
Организация обучения даёт существенную экономию памяти: в каждой итерации случайно выбирается только один блок, остальные блоки не вычисляются, поэтому пиковая память соответствует примерно L/B слоям, а не всем L. В отличие от activation checkpointing, которое экономит память только на активациях, но не уменьшаёт объём памяти, занятой параметрами, градиентами и состояниями оптимизатора Adam (в сумме ≈4×параметры на слой), блок‑овый подход снижает общий объём памяти пропорционально числу блоков B.
Авторы вводят также концепцию equi‑probability partitioning: границы между блоками выбирают так, чтобы каждый блок покрывал ровно 1/B вероятностной массы p_noise. Это важно, потому что при log‑normal распределении именно промежуточные уровни шума дают наибольший вклад в качество генерации, и простое равномерное деление диапазона по значению σ приведёт к неравномерной нагрузке между блоками.
На фоне предыдущих локальных методов обучения (Forward‑Forward, greedy layer‑wise training), которые обычно опираются на эвристические локальные цели и уступают end‑to‑end подходам, DiffusionBlocks претендует на сокращение теоретического разрыва и расширение применимости локального обучения за пределы задач классификации. Практически это означает, что инженерам придётся преобразовать архитектуру и добавить шумовой conditioning, а подробности реализации и экспериментальные результаты доступны в apXiv‑докладе.
Источники
Ответы (0)
Пока нет ответов в этой теме.