Stability AI выпустила Stable Audio 3, семейство латентных диффузионных моделей для генерации и редактирования звука. В релизе доступны открытые веса для вариантов small и medium; масштаб large предлагается по enterprise‑лицензии. Вместе с кодом компания опубликовала техдок и результаты бенчмарков. Модели генерируют стерео‑аудио с частотой дискретизации 44.1 kHz, поддерживают переменную длину выходов, редактирование через инпейтинг и оптимизированы для быстрого инференса. Семейство включает три масштаба: small (две версии: music и sfx, по 459M параметров диффузионного трансформера, до 2 минут), medium (1.4B параметров, до 6 минут 20 секунд) и large (2.7B параметров, до 6 минут 20 секунд).
Архитектура состоит из двух компонентов: автоэнкодера SAME (Semantically‑Aligned Music autoEncoder) и диффузионного трансформера, работающего в латентном пространстве SAME. Для small используется SAME‑S (108M параметров, оптимизирован для CPU), для medium и large — SAME‑L (852M параметров). Открытые веса small и medium доступны на Hugging Face, large — по коммерческой лицензии. По бенчмарку BBC Sound Effects на отрезке 5 секунд версия SA3 medium получила FAD 0.369 — показатель ниже, чем у всех открытых весов, включённых в оценку статьи. Это сравнение указывает на конкурентоспособность качества генерации среди моделей с открытыми весами, но полный доступ к наилучшему масштабу требует коммерческой лицензии.
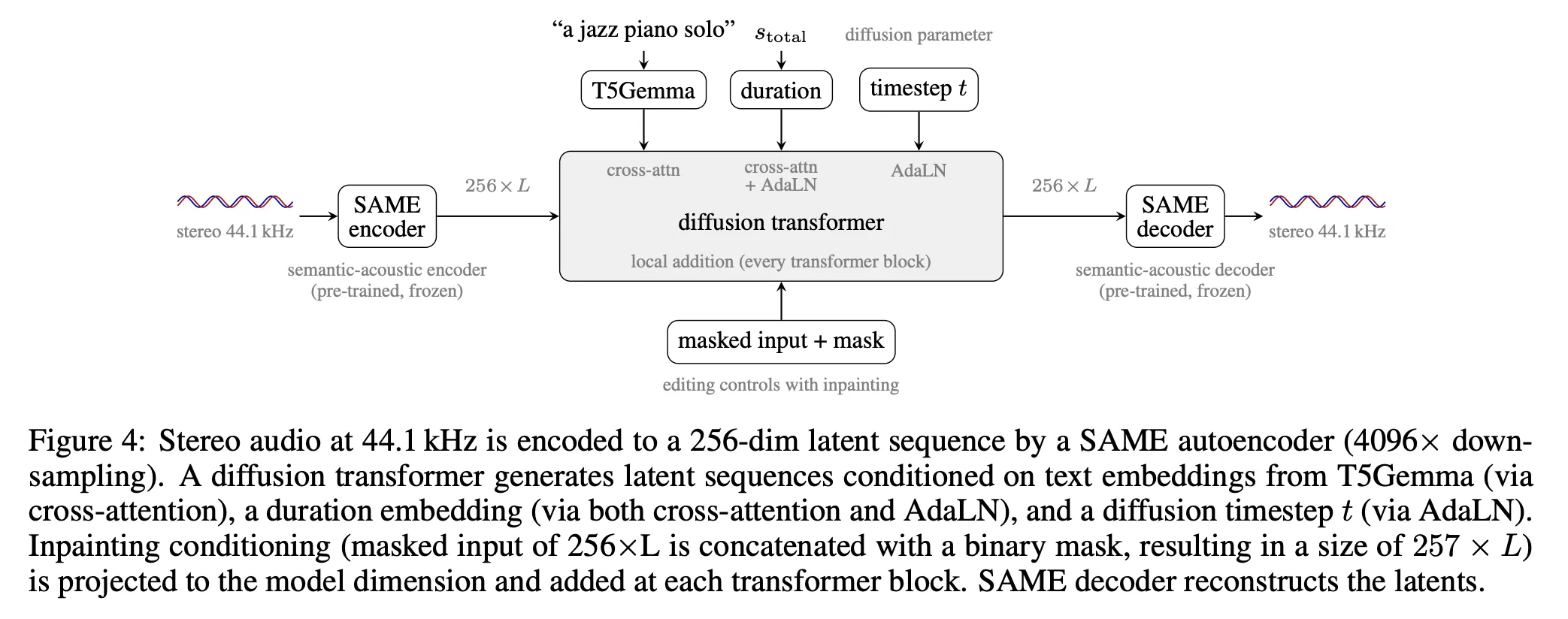
Тренировочная пайплайн включает три стадии: flow matching, distillation warmup и adversarial post‑training — комбинация, направленная на баланс скорости инференса и качества звука. SAME фиксируется (frozen) при обучении диффузионного трансформера; для разработчиков это значит, что генератор оперирует над стабильным латентным представлением, а дообучение диффузионной части отделено от обучения автоэнкодера. SAME достигает суммарного 4096× понижения разрешения: сначала патчинг — неперекрывающиеся патчи по 256 сэмплов на канал (256×), затем Transformer Resampling Block даёт дополнительное 16× сжатие, итогом становится латентная последовательность размерности 256 при ≈10.76 Hz для входа 44.1 kHz. SAME обучается с пятью типами лоссов (спектральная реконструкция, adversarial, diffusion alignment, семантическая регрессия — хрома и межуровневый размах уровня, и контрастная выравнивающая потеря).
текст (замороженный T5Gemma → 256 эмбеддингов по 768), длительность (Fourier‑фичи, вводимые через AdaLN и cross‑attention) и маску инпейтинга (2‑слойный MLP), а блоки трансформера включают self‑ и cross‑attention, локальную аддитивную кондицию для инпейтинга, SwiGLU и (в medium/large) differential attention; трансформер также добавляет 64 обучаемых memory‑эмбеддинга.
Источники
Ответы (0)
Пока нет ответов в этой теме.