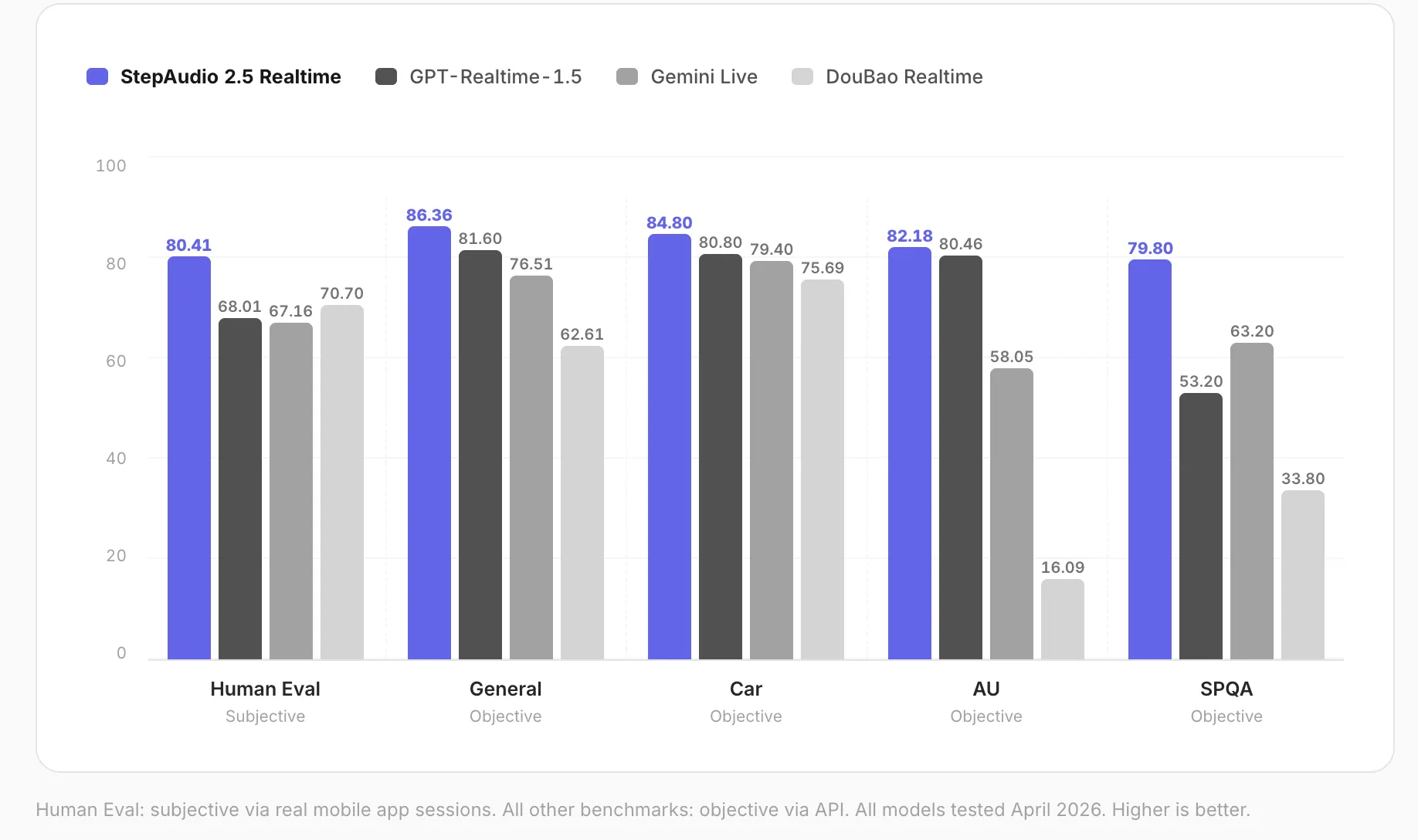
В мае 2026 шанхайская лаборатория StepFun представила StepAudio 2.5 Realtime — end-to-end модель для реального времени, обеспечивающую вход‑в‑выход аудио в единой системе и полностью настраиваемые «персоны».
StepFun объявила в мае 2026 о выпуске StepAudio 2.5 Realtime — голосовой модели, работающей в реальном времени и ориентированной на ролевые взаимодействия (roleplay‑specific RLHF) с паралингвистическим пониманием. Это важное обновление для приложений, которым нужна живая, персонализированная голосовая интеракция, поскольку модель сочетает генерацию речи и управление «персонами» в одном потоке обработки, уменьшая задержки и рассогласования между компонентами. StepAudio 2.5 Realtime построена как истинная end-to-end система: аудио подаётся на вход, а аудио выходит из единой архитектуры без последовательного разделения на отдельные этапы распознавания речи, рассуждений и синтеза. Такой подход отличает её от конвейерных систем, где каждый модуль функционирует отдельно, и обещает более согласованное поведение голоса и интонации при продолжительных и сложных диалогах.
Модель поддерживает китайский и английский языки и рассчитана на работу в режиме реального времени через WebSocket API. Точка подключения указана как wss: //api.stepfun.com/v1/realtime; идентификатор модели в запросах — step-2.5 — realtime. Эти параметры сохраняют совместимость с приложениями, ориентированными на интерактивные голосовые интерфейсы. Исследовательская команда StepFun называет три ключевых архитектурных новшества, лежащих в основе StepAudio 2.5 Realtime; в доступных материалах подробно раскрыт первый из них. Этот первый столп — масштабное дополнение данных о «персонах»: начиная с более чем 10 000 высококачественно и нативно созданных профилей персон, StepFun применил алгоритмическое расширение, чтобы построить матрицу признаков «персон» масштабом до миллиона.
Полученную матрицу комбинировали с миллионами реальных разговорных примеров при обучении, чтобы повысить способность модели к генерализации и устойчивость на сложных, редких (long‑tail) темах. Вместо ручного разметывания миллионов примеров способ взаимодействия с данными основан на алгоритмическом расширении начального набора — то есть команда формировала большие вариации персонажей из кураторного «зерна» данных. По заявлению разработчиков, такая методика направлена на стабильное воспроизведение заданных характеров и поведения в широком спектре диалоговых сценариев без необходимости индивидуальной постразметки для каждой вариации.
Источники
Ответы (0)
Пока нет ответов в этой теме.