Корейская Supertone выпустила Supertonic 3 — компактный on‑device синтезатор речи в публичных ONNX‑ассетах с поддержкой 31 ISO‑кода, улучшенной экспрессией и совместимостью с предыдущими интеграциями.
Supertone выпуском Supertonic 3 представила третье поколение on‑device синтезатора речи, поставляемого в публичных ONNX‑ассетах; контракт вывода (inference contract) остался совместим с предыдущими интеграциями, что упрощает обновление существующих устройств и приложений. Это релиз ориентирован на краевое и локальное развёртывание TTS-модель компактна и рассчитана на работу без облака.
Языковая поддержка в Supertonic 3 выросла с пяти до 31 ISO‑кода: добавлены японский, арабский, болгарский, чешский, датский, немецкий, греческий, эстонский, финский, хорватский, венгерский, индонезийский, итальянский, литовский, латвийский, нидерландский, польский, румынский, русский, словацкий, словенский, шведский, турецкий, украинский и вьетнамский; предусмотрён специальный fallback na для неизвестного языка. Публичные ONNX‑ассеты занимают в сумме 404 MB, а модель содержит около 99 миллионов параметров — заметно меньше моделей класса 0.7 — 2B, что сокращает объём загрузки и время старта.
Архитектура унаследована от предыдущих релизов: речевой автоэнкодер кодирует волны в непрерывные латенты, текст‑в‑латент реализован через подход на базе flow matching, а предиктор длительностей отвечает за естественный тайминг. В процессе обучения использованы Length‑Aware Rotary Position Embedding (LARoPE) и Self‑Purifying Flow Matching. Модель достигает рабочей генерации при минимальном числе шагов (например, в два шага), что даёт преимущество по скорости перед диффузионными методами при низком числе шагов.
По практической устойчивости команда отмечает снижение частоты повторных и пропускных ошибок чтения и улучшение сходства говорителя по сравнению с v2. Для оценки читабельности вывода используется транскрипция синтезированного аудио через ASR, по которой считаются WER (word error rate) и CER (character error rate); по этим метрикам Supertonic 3 остаётся в конкурентном диапазоне относительно более крупных открытых TTS‑моделей вроде VoxCPM2.
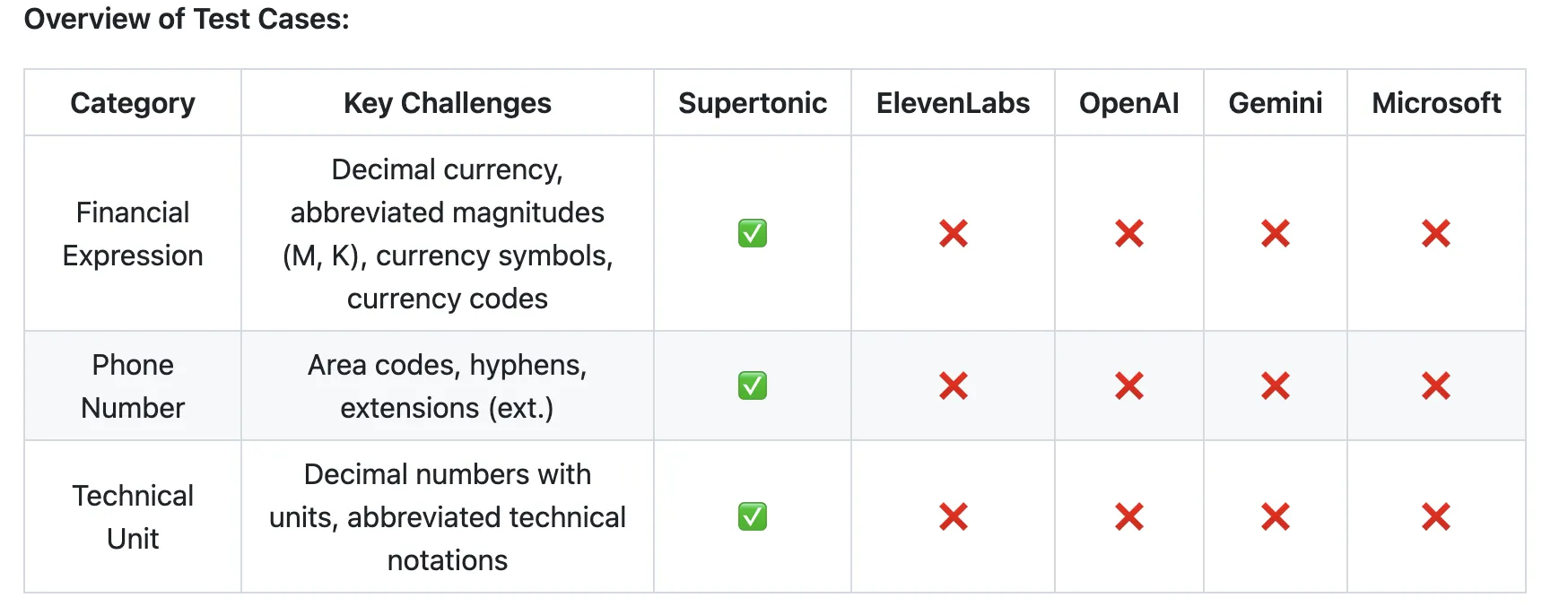
Новая поддержка expressive tags позволяет вставлять просодические подсказки прямо в текст — например, указать дыхательную паузу или смех — без дополнительной предобработки или отдельной модели экспрессии. При этом сохранена продвинутая нормализация текста: корректное проговаривание финансовых форматов вроде $5.2M, номеров с кодами и добавками ((212) 555‑0142 ext. 402), дат и времени (пример: 4:45 PM on Wed, Apr 3, 2024) и технических единиц.
Релиз явно ориентирован на разработчиков: публичные ONNX‑ассеты обратимо совместимы с v2, экосистема расширилась — доступны сборки для Flutter (с поддержкой macOS),.NET 9 и Go, а веб‑вариант использует onnxruntime‑web для чисто клиентской работы. Supertonic 3 эффективно работает на CPU и демонстрирует средний RTF 0.3x на e‑ink устройстве Onyx Boox Go 6 в режиме полёта, что упрощает развёртывание в локальных, браузерных и краевых сценариях. Кроме того, Supertone запустила Voice Builder — инструмент для создания кастомных edge‑native TTS‑моделей на основе собственных записей голоса, позволяющий интегрировать персонализированные озвучки при сохранении компактности on‑device архитектуры.
Источники
Ответы (0)
Пока нет ответов в этой теме.