Together AI опубликовала исходники OSCAR-систему INT2‑квантования KV‑кэша, предназначенную для обслуживания больших языковых моделей с длинными контекстами. OSCAR расшифровывается как Offline Spectral Covariance — Aware Rotation; проект открыт и нацелен на практическое использование в продакшн‑стеке, поскольку сочетает существенную экономию памяти с ускорением декода при экстремально длинных контекстах. Это важно для сервисов, где KV‑кэш — основной ограничивающий ресурс при работе с контекстами большого размера.
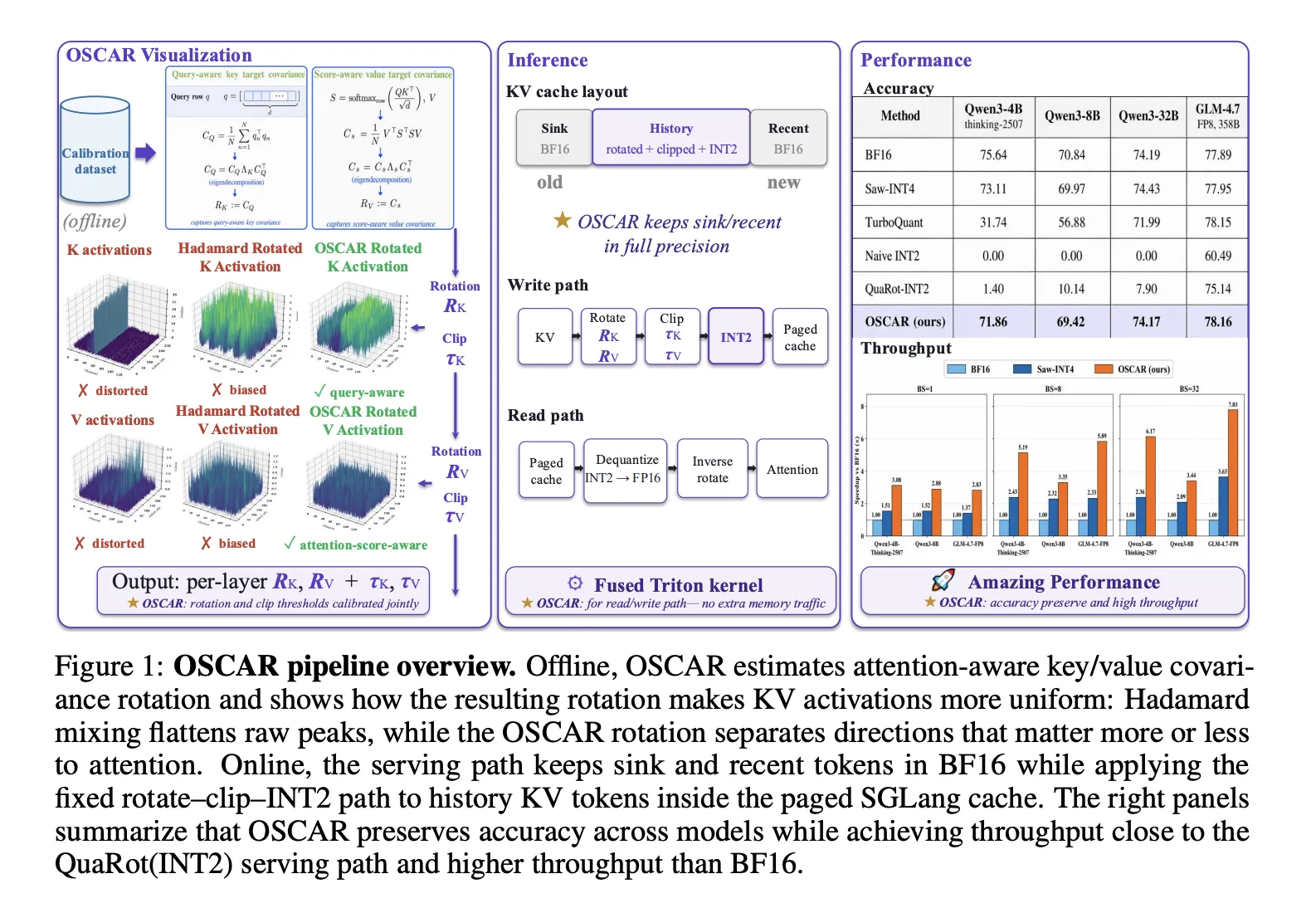
Техническая идея OSCAR основана на офлайн‑сборе статистик внимания и построении отдельных ортогональных вращений для ключей и значений. Для ключей оценивается ковариация CQ = (1/N) Σ qn⊤qn, собственные векторы которой UQ используются как базис вращения. Для значений вводится score‑взвешенная ковариация CS = (1/N) V⊤S⊤SV, собственные векторы US служат базисом для значений. Такое разделение позволяет захватывать разные структуры важности в Q и V и адаптировать представление под них.
Итоговые вращения собираются композиционно: RK = UQ · HHad · Pbr и RV = US · HHad · Pbr. Здесь HHad — Уолш‑Хадамард‑преобразование, применяемое для выравнивания важности каналов, а Pbr-перестановка бит‑реверса, распределяющая уровни важности по группам квантования. UQ и US выравнивают направления важности внимания; в сумме эти шаги подготавливают каналы для эффективного INT2‑квантования. Проблема, которую решает OSCAR, — канал‑по‑канальным выбросам: редкие пики в отдельных каналах доминируют шкалу квантайзера и «съедают» представимый диапазон, что особенно критично при INT2. Ранее применявшиеся фиксированные, data‑oblivious трансформы (обычно Hadamard) работали приемлемо для INT4, но при INT2 не могли направлять ошибку в низковажные направления. OSCAR учитывает структуру Q⊤Q и S‑взвешенные структуры V, что позволяет ограничить влияние выбросов на важные направления внимания.
В экспериментах при среднем размере 2.28 бита на элемент KV OSCAR показал сокращение разрыва по точности относительно BF16 на 3.78 процентных пункта на Qwen3-4B‑Thinking‑2507 и на 1.42 пункта на Qwen3-8B. Одновременно система обеспечивает примерно 8× уменьшение объёма KV‑памяти и до 3× ускорение декода при длине контекста 100K токенов — показатели, значимые для реальных сервисов с длинными историями диалога или архивными контекстами.
Для практического развёртывания OSCAR уже интегрирован в производство SGLang как режим INT2 KV‑кэша; реализация совместима с paged‑attention и существующими layout‑ами. KV‑кэш использует смешанно‑точный формат: первые S0 = 64 «sink tokens» сохраняются в BF16, остальная часть кэша хранится в INT2‑формате OSCAR для экономии памяти и пропускной способности. Авторы также привели формальные утверждения: лемма показывает, что HHad равномерно выравнивает диагонали (diag entries = tr(Λ)/d), а Теорема 1 доказывает оптимальность UQ/US при фиксированном приближённом критерии ошибки с диагональными остатками. Эти теоретические гарантии подкрепляют практическую эффективность и совместимость метода.
Источники
Ответы (0)
Пока нет ответов в этой теме.