Zyphra описала Tensor and Sequence Parallelism (TSP) — метод «складывания» параллелизмов, при котором TP и SP выполняются вдоль одной оси шардирования, что уменьшает и параметрическую, и активационную память на каждом устройстве.
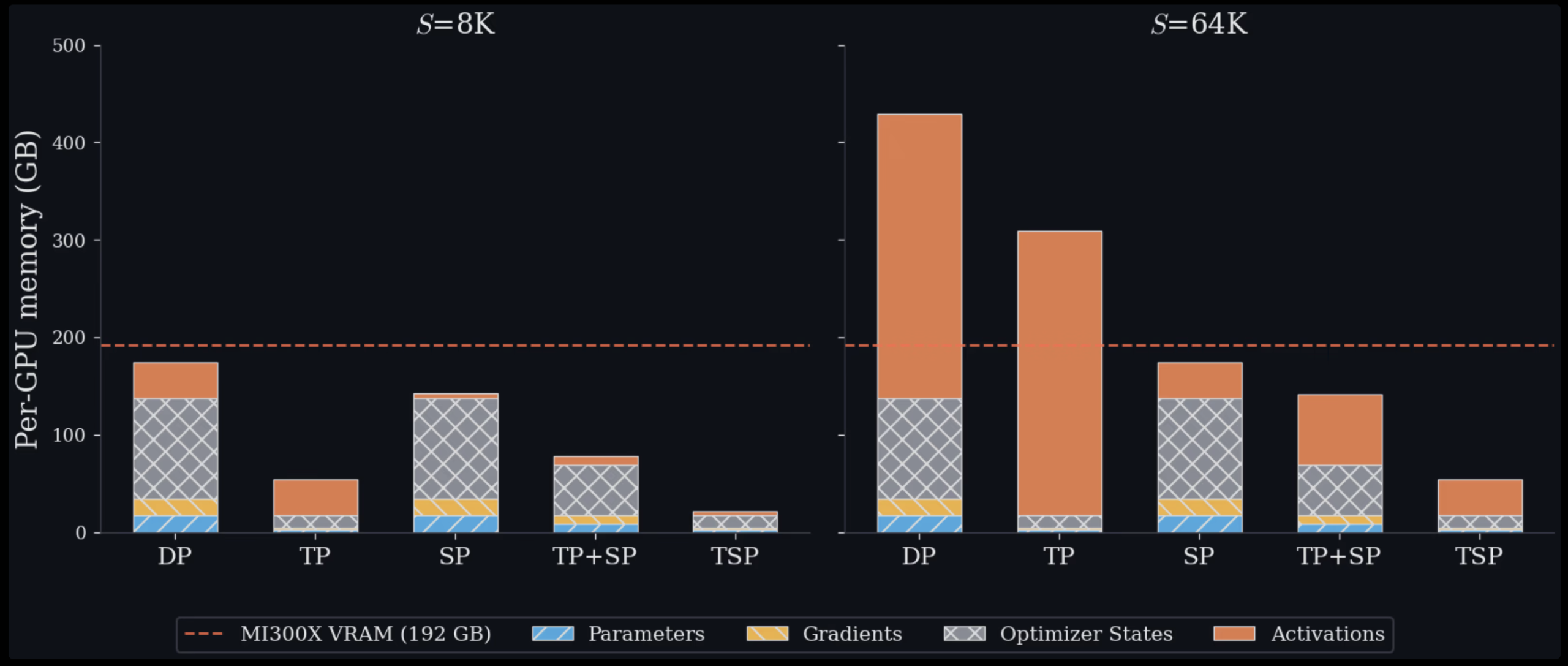
TSP-это предложенный Zyphra подход к распределению работы для тренировки и сервирования больших трансформеров, направленный на ключевую проблему: ограниченную VRAM на каждой GPU. Метод изменяет привычные компромиссы между экономией памяти параметров и памяти активаций, предлагая иной способ шардировать ресурсы в пределах одной группы устройств. Ключевая идея — «параллелизм в сложенном виде»: вместо размещения Tensor Parallelism (TP) и Sequence Parallelism (SP) по ортогональным осям mesh‑топологии, TSP складывает оба параллелизма вдоль одной оси размера D. В результате каждая GPU одновременно хранит 1/D от весов и 1/D от входной последовательности, что понижает на 1/D и модель‑стейт (параметры, градиенты, optimizer state), и активации на устройстве.
Реализация требует координации для выполнения слоёв: для внимания Zyphra описывает итерацию по шард‑весам, когда одна GPU вещает упакованные блоки WQ, WK, WV и WO всем остальным; каждая нода вычисляет локальные Q/K/V проекции над своими токенами; затем локальные K и V собираются (all‑gather), переупорядочиваются с использованием zigzag‑partition и подаются в FlashAttention. Для gated MLP применяется отдельный граф коммуникаций, оптимизированный под раздельные шард‑веса и шард‑активации.
В сравнении с традиционными схемами: TP уменьшает память параметров но вызывает дорогостоящие коллективные операции, пропорциональные размеру активаций; SP режет память активаций но реплицирует веса; а комбинирование TP и SP по двум осям требует T·Σ устройств и может вынуждать коммуникацию через медленные междуузловые соединения. TSP достигает сокращения и параметрической, и активационной памяти на одной оси без двухмерного раскроя T·Σ.
В бенчмарках Zyphra сообщает снижение пиковой памяти на GPU по сравнению со стандартными схемами и прирост до 2.6× по пропускной способности относительно сопоставимых TP+SP‑базелайнов на конфигурациях до 1,024 AMD MI300X. Это означает, что на тех же GPU можно обслуживать большие модели или более длинные контексты, либо высвободить устройства для дополнительных data‑parallel реплик. Для инженеров и строителей кластеров практический эффект TSP-новый инструмент в оптимизации памяти и пропускной способности, но он требует реализации специальных коммуникационных расписаний и поддержки шардирования как весов, так и токенов по одной оси. Подробности по коммуникациям и порядку операций Zyphra публикует в техническом посте с реализационными примерами.
Источники
Ответы (0)
Пока нет ответов в этой теме.