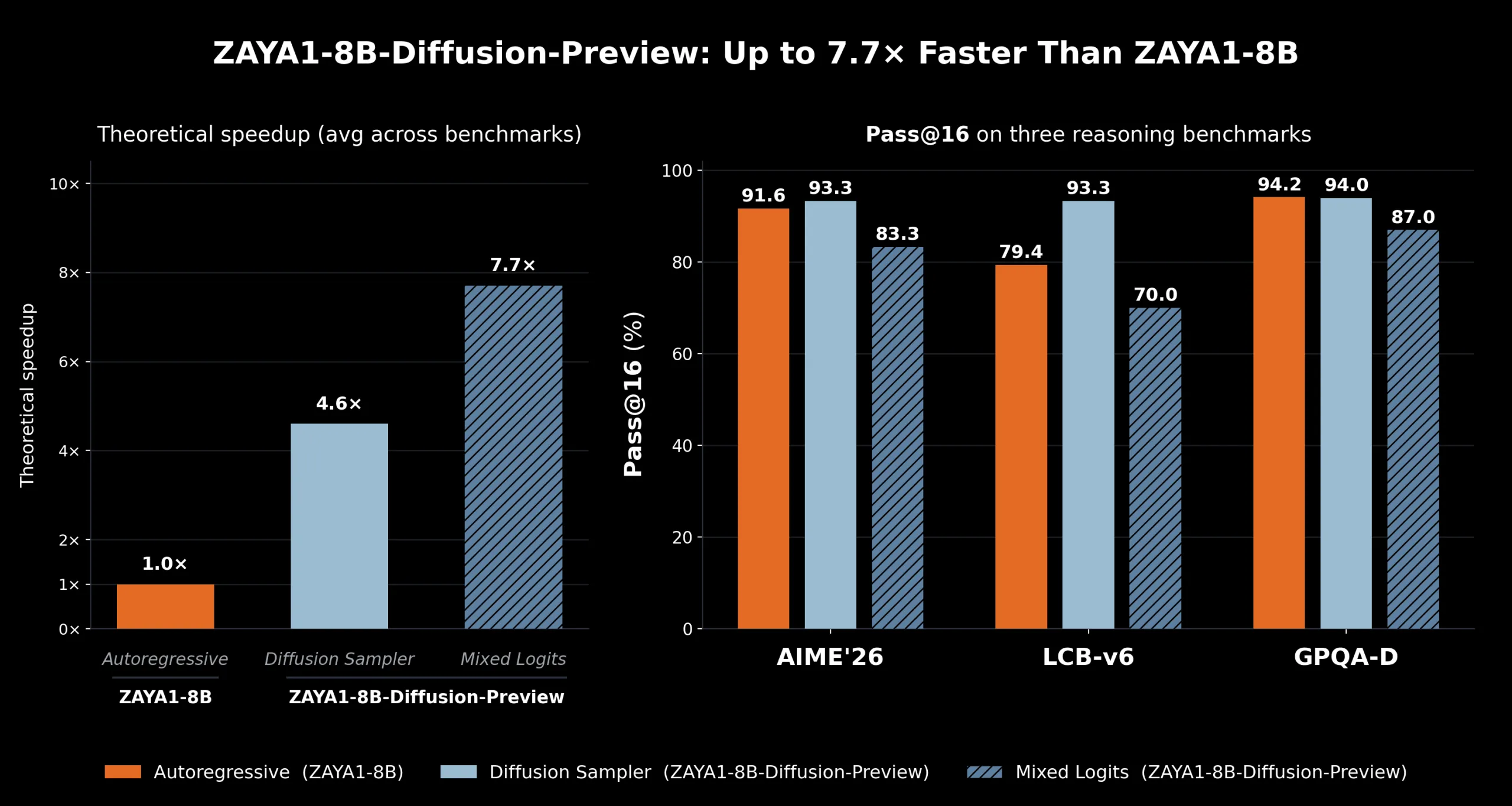
Zyphra выпустила превью ZAYA1-8B‑Diffusion‑Preview — конверсию автрорегрессионной MoE‑модели в дискретную диффузионную модель, обеспечивающую до 7,7× ускорения вывода на AMD за счёт пакетной генерации токенов и совместного KV‑кеша.
Zyphra опубликовала превью ZAYA1-8B‑Diffusion‑Preview: конверсию своей автрорегрессионной MoE‑модели в дискретную диффузионную архитектуру, которая при демонстрационных условиях ускоряет вывод на AMD‑аппаратуре до 7,7×. Это важно, потому что решение адресует аппаратное узкое место автрорегрессионного декодирования и позволяет получить заметный прирост пропускной способности вывода без полного переобучения модели с нуля.
Технически релиз опирается на чекпоинт ZAYA1-8B‑base и рецепт TiDAR. Команда провела три фазы: 600 миллиардов токенов дополнительной конверсии в режиме диффузии при контексте 32k, затем 500 миллиардов токенов нативного расширения контекста до 128k и финальную фазу diffusion SFT. Zyphra подчёркивает одноступенчатый переход «маска→токен» для каждого токена в блоке и отмечает, что это первая MoE‑диффузионная модель, конвертированная из автрорегрессионного LLM, а также первая диффузионная языковая модель, обучавшаяся на AMD GPU.
Проблема, которую команда решает, — ограничение автрорегрессионного декодирования: при по‑токенной генерации внимание требует последовательной загрузки индивидуальных KV‑кэшей из памяти для каждого запроса, что делает вывод привязанным к пропускной способности памяти. Поскольку современные GPU увеличивают FLOPs быстрее, чем память, это приводит к неэффективному использованию вычислительных ресурсов и сдерживает прирост производительности при автрорегрессивном подходе.
В ZAYA1-8B‑Diffusion‑Preview диффузионная схема генерирует блоки одновременно и использует общий KV‑кэш для всех N токенов в блоке, сдвигая нагрузку в сторону вычислений. В демонстрации модель формирует черновик из 16 токенов за проход; часть токенов принимается по критерию выборки, заимствованному у speculative decoding. Архитектурно та же модель выполняет роль и спекулятора, и верификатора в одном проходе, что исключает накладные расходы на запуск двух отдельных моделей, как в подходах EAGLE или dFlash.
Zyphra утверждает, что в сильно memory‑bandwidth‑bound режимах принятые токены дают почти «бесплатное» ускорение по сравнению с последовательным автрорегрессивным декодированием: GPU уже загружен, а добавление принятых токенов требует минимального дополнительного compute. Команда также упоминает два сэмплера с разными скоростными компромиссами и акцентирует, что конверсия позволяет повторно использовать существующую предтренировочную базу, концентрируя выгоды именно на этапе вывода. Вывод для разработчиков и инженеров прост: конверсия автрорегрессионного MoE в диффузионный режим может обеспечить практическое ускорение вывода при минимальном ухудшении метрик и без необходимости полного обучения диффузионной модели с нуля — по мнению Zyphra, последнее технически сложно и даёт мало преимуществ для этапа тренировки, поскольку узкое место остаётся в выводе.
Источники
Ответы (0)
Пока нет ответов в этой теме.