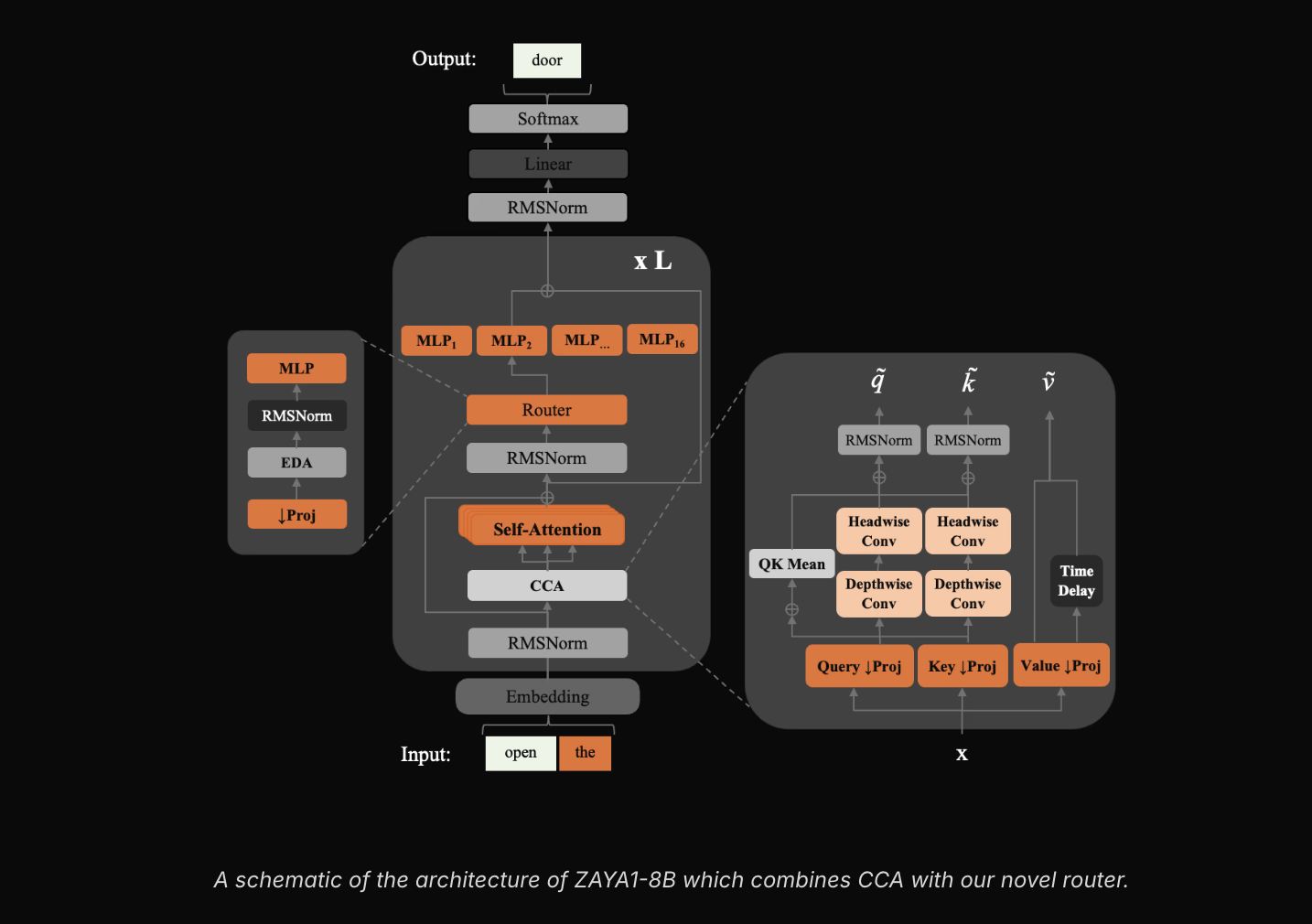
Zyphra сделала публичной модель ZAYA1-8B: её веса выпущены под лицензией Apache 2.0 на Hugging Face, а сама модель доступна как serverless‑эндпойнт в Zyphra Cloud. Поставщики и разработчики могут либо скачивать веса, либо вызывать модель по облачному API без дополнительных проприетарных ограничений лицензии. По конструкции ZAYA1-8B-Mixture of Experts (MoE) семейства Zyphra MoE++ с суммарно 8,4 млрд параметров и только 760 млн активных параметров при одном инференс‑проходе. Такой подход означает, что для каждого запроса задействуется ограниченный набор «экспертов», что снижает вычислительные и требования к KV‑кешу по сравнению с эквивалентными по представительности плотными моделями.
Zyphra выделяет три ключевые архитектурные инновации в MoE++: Compressed Convolutional Attention (CCA) — механизм для сжатого представления attention, который сокращает объём KV‑кеша примерно в 8×; MLP‑роутер с PID‑контролем для более равномерного распределения нагрузки между экспертами; и learned residual scaling для контроля роста норм остаточных потоков без существенного увеличения числа параметров. На эталонных наборах ZAYA1-8B демонстрирует конкурентоспособные результаты в задачах рассуждений: модель обходит некоторые открытые веса большей размерности в задачах математики и программирования и близка по показателям к DeepSeek V3.2. В частности, при использовании метода Markovian RSA на наборе HMMT'25 ZAYA1-8B набирает 89.6 балла против 88.3 у Claude 4.5 Sonnet и превосходит GPT‑5‑High в этом тесте.
Для инженеров и интеграторов это означает практическую экономию ресурсов: более низкие требования к инференсу и уменьшенный KV‑кеш облегчают развёртывание в локальных или гибридных средах, дают возможность увеличивать эффективный контекст и уменьшают латентность по сравнению с плотными моделями тех же бенчмарков. Открытая лицензия Apache 2.0 упрощает использование и доработку модели в продакшене и интеграцию в существующие стеки.
Стек обучения также подчёркнуто масштабный: предобучение, промежуточная дообучка и SFT выполнялись полностью на кластере из 1,024 узлов AMD Instinct MI300x, соединённых через AMD Pensando Pollara interconnect, в кастомном обучающем окружении, собранном с участием IBM. Пост‑тренировочный пайплайн Zyphra включает пятиступенчатую обработку, в том числе SFT, reasoning‑warmup и крупную фазу RLVE‑Gym, а также методики reasoning RL cascade и Markovian RSA для тестового режима и повышения качества рассуждений. В практическом доступе остаются оба варианта работы с моделью: локальная деплойка на собственном железе при экономии ресурсов или обращение к serverless‑эндпойнту Zyphra Cloud для быстрого интеграционного использования и тестирования новых сценариев.
Источники
Ответы (0)
Пока нет ответов в этой теме.