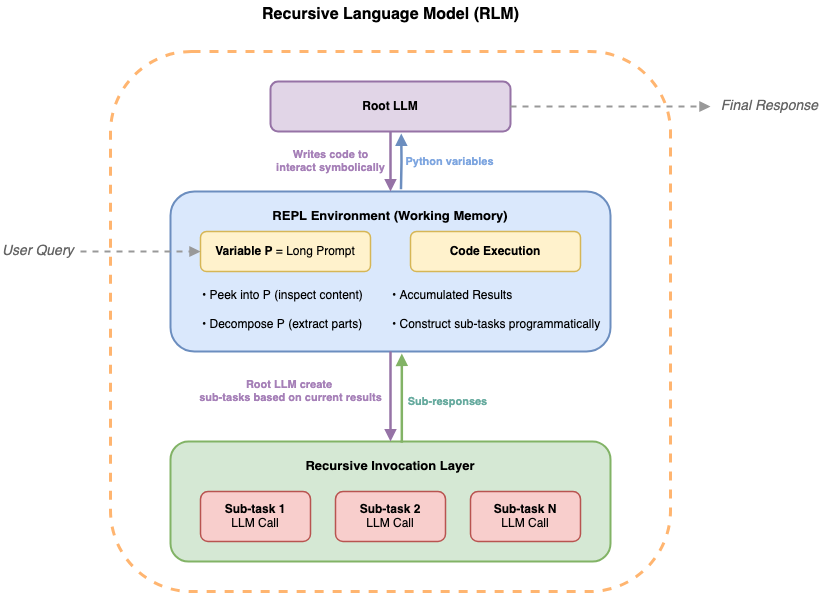
Un tutorial técnico describe cómo implementar Recursive Language Models (RLM) usando Amazon Bedrock AgentCore Code Interpreter y el Strands Agents SDK para analizar documentos de gran tamaño sin cargar el texto completo en la ventana de contexto del LLM raíz. El método permite respuestas iterativas y dirigidas al separar la lógica de control del contenido, lo que desconecta el tamaño del documento del límite de contexto y facilita análisis a escala.
El enfoque trata el contenido como un entorno externo: el LLM raíz recibe solo la consulta y una descripción del entorno y, a partir de ello, genera código para localizar, fragmentar y analizar secciones del documento. Ese código delega tareas semánticas a sub — LLMs especializados, coordinando búsquedas, resúmenes o comparaciones en pasos sucesivos y acumulando resultados fuera de la ventana de contexto principal.
Bedrock AgentCore Code Interpreter funciona como memoria de trabajo persistente dentro de un sandbox Python, donde los resultados se almacenan en variables y estructuras de datos en lugar de ocupar la ventana de contexto del modelo central. Esa memoria de trabajo permite orquestar llamadas a sub — LLMs, iterar sobre fragmentos y conservar salidas parciales para ensamblar un análisis global sin reintroducir el documento completo al LLM raíz.
El tutorial ilustra la necesidad con ejemplos prácticos: informes anuales de 300 — 500 páginas, informes de analistas y documentos regulatorios que suman millones de caracteres suelen provocar errores por límite de contexto o respuestas que omiten información en el medio. Cita además la referencia académica que formaliza la idea (Zhang et al., arXiv:2512.24601). En la práctica, la técnica facilita flujos de trabajo iterativos para análisis financieros extensos, auditorías y revisión documental a escala, al permitir orquestar tareas específicas desde un entorno Python aislado y acumular los resultados en memoria persistente.
Fuentes
Respuestas (0)
Aún no hay respuestas en este tema.