Una nueva guía técnica expone una arquitectura de observabilidad diseñada para modelos de lenguaje a gran escala (LLM) servidos desde endpoints de Amazon SageMaker IA. El documento propone integrar señales operativas y métricas de calidad para conseguir una visibilidad holística de despliegues de inferencia a escala, de modo que los equipos puedan correlacionar el comportamiento de la infraestructura con la fidelidad y seguridad de las respuestas generadas por los modelos.
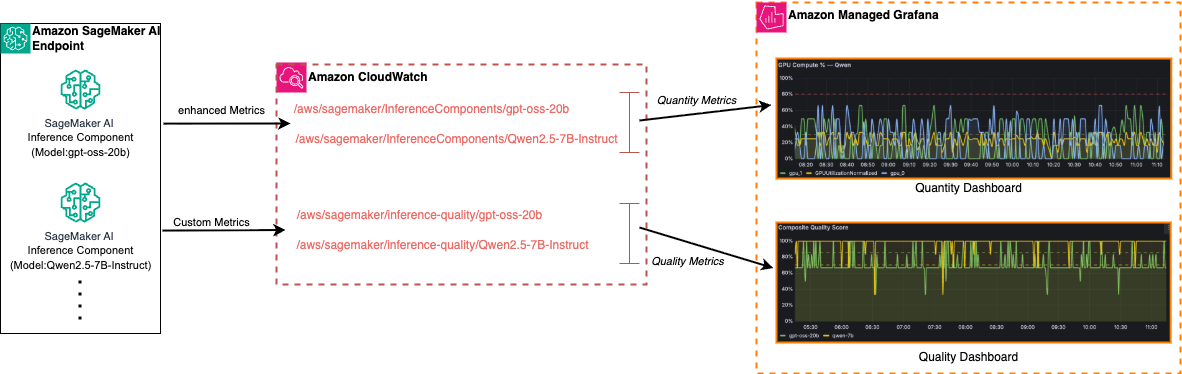
La arquitectura se apoya en tres componentes centrales: endpoints de Amazon SageMaker IA que ejecutan inference components, Amazon CloudWatch como sistema de almacenamiento y ingestión de métricas, y Amazon Managed Grafana como capa de visualización y análisis. Un único endpoint de SageMaker IA puede alojar múltiples inference components — el ejemplo citado incluye gpt-oss-20b y Qwen2.5 — 7B-Instruct—, lo que permite comparar y operar distintos modelos y configuraciones dentro de la misma topología de servicio.
La guía argumenta que la observabilidad para LLM debe abordar dos dimensiones complementarias: cantidad y calidad. La dimensión de cantidad agrupa métricas operativas clásicas — volumen de solicitudes, utilización de CPU y GPU, latencias e incidencias—, mientras que la dimensión de calidad abarca indicadores sobre la precisión, seguridad y coherencia de las predicciones generadas. Según el documento, medir y correlacionar ambas dimensiones es esencial para identificar fallos reales en producción que no se detectan sólo con métricas infraestructurales.
En la implementación propuesta, cada inference component envía a CloudWatch dos flujos de datos diferenciados: enhanced metrics y custom quality metrics. Las enhanced metrics se publican automáticamente cuando se habilitan e incluyen señales a nivel de instancia, contenedor y GPU; se registran bajo rutas como /aws/sagemaker/InferenceComponents/ (por ejemplo /aws/sagemaker/InferenceComponents/gpt-oss-20b). Las métricas de calidad personalizadas se publican en /aws/sagemaker/inference — quality/ y comprenden composite quality scores, safety scores y evaluation latency, entre otras medidas diseñadas para evaluar salidas del modelo.
Amazon Managed Grafana consume CloudWatch como fuente nativa y la guía recomienda dos paneles básicos y extensibles: un dashboard focalizado en la dimensión de cantidad — con métricas como GPU memory utilization, CPU usage e invocation metrics por inference component— y otro dedicado a la dimensión de calidad — comparando composite quality scores, safety scores y evaluation latency entre modelos y versiones. Estos paneles permiten visualizar tendencias temporales, comparar modelos y detectar divergencias entre salud operativa y calidad del output.
Desde el punto de vista operativo, el monitoreo de cantidad facilita la detección de cuellos de botella, el dimensionamiento adecuado del cómputo y el control de costes ante patrones de consumo variables. La guía señala que las cargas generativas amplían la incertidumbre en consumo de tokens, presión de memoria GPU y picos de latencia, lo que complica la planificación de capacidad; por ello, las enhanced metrics ayudan a identificar cuándo y dónde se producen estas tensiones.
La incorporación de métricas de calidad permite cerrar el círculo: mediante muestreo de respuestas, evaluaciones automatizadas y scoring compuesto se identifican drift, degradación o comportamientos inesperados que no siempre coinciden con señales infraestructurales. La propuesta enfatiza la definición de umbrales y alertas que consideren señales combinadas de infraestructura y calidad para activar acciones como escalado, rollback de modelos o bloqueo de salidas degradadas. La hoja de ruta operativa que describe la guía sugiere etapas sucesivas: comenzar por visibilidad en métricas operativas básicas (latencia, errores, utilización), introducir calidad mediante muestreo y métricas de evaluación para detectar problemas de coherencia o seguridad, y evolucionar hacia análisis comparativos entre modelos y configuraciones que informen decisiones de despliegue. Con el tiempo, los paneles de Managed Grafana pueden extenderse para soportar requisitos específicos de negocio y casos de uso concretos.
En conclusión, la guía sostiene que la observabilidad de grado productivo para inferencia LLM se alcanza cuando las dimensiones de cantidad y calidad se miden, correlacionan y optimizan de forma conjunta. Esta aproximación permite detectar problemas reales en producción — ya sean cuellos de botella en GPU o degradación en la calidad de las respuestas— y define un marco operativo para alertas automatizadas, análisis comparativo y ajuste de capacidad y modelos sin perder de vista tanto la salud operativa como la calidad del output.
Fuentes
Respuestas (0)
Aún no hay respuestas en este tema.