Tomofun, la startup taiwanesa creadora de la Furbo Pet Camera, ha migrado la inferencia de sus modelos visión‑lenguaje BLIP desde instancias GPU a instancias EC2 Inf2 impulsadas por chips Inferentia2. La decisión responde al elevado coste de mantener inferencia «always‑on» para la detección de comportamientos de mascotas — ladridos, carreras y actividad inusual— y a la necesidad de sostener precisión y throughput en tiempo real sin degradar las alertas.
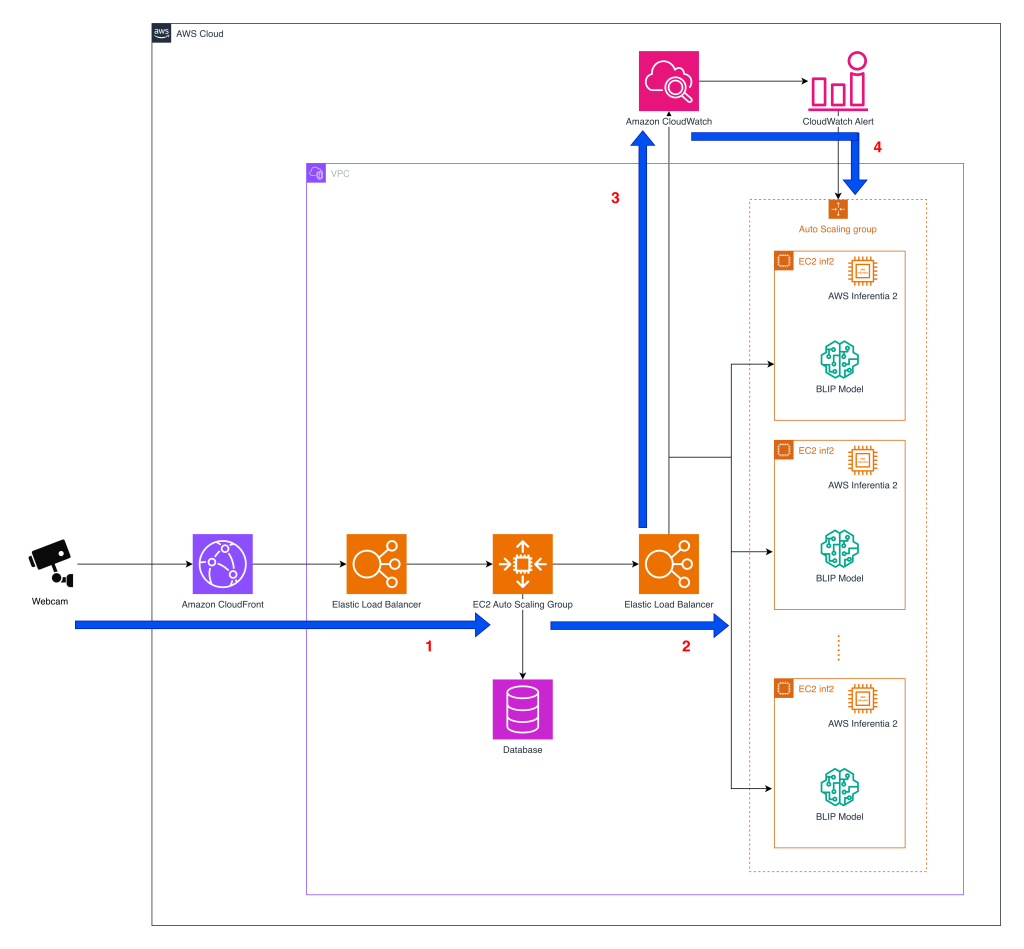
En la arquitectura descrita, los marcos de cámara llegan a través de Amazon CloudFront y pasan por un Elastic Load Balancer hacia una primera capa de servidores API en un Auto Scaling group. Desde ahí cada imagen se reenvía a una segunda capa, también en Auto Scaling, dedicada exclusivamente a la inferencia. En esa capa, contenedores cargan componentes del modelo BLIP que fueron compilados con Neuron SDK y los ejecutan sobre instancias EC2 Inf2 con Inferentia2.
Antes de la migración, las cargas BLIP corrían sobre instancias EC2 con GPU; esas instancias ofrecen alto rendimiento, pero resultan costosas para inferencia continua a gran escala. Tomofun necesitaba monitorización casi constante para cientos de miles de dispositivos, conservar la fidelidad del modelo y mantener throughput sin tener que reescribir grandes porciones del código BLIP optimizado en PyTorch.
Compilar componentes de BLIP con Neuron SDK permitió ejecutar el modelo en Inf2 sin rehacer la base PyTorch, ofreciendo una vía práctica para desplegar modelos visión‑lenguaje siempre activos a escala. La implementación separa claramente la capa de API de la de inferencia y se presenta en el blog técnico como un recorrido detallado para reducir costes operativos mientras se mantienen las alertas en tiempo real.
Fuentes
Respuestas (0)
Aún no hay respuestas en este tema.