Команды Amazon Finance разработали масштабируемое приложение на базе Amazon Bedrock и сопутствующих AWS‑сервисов с RAG и векторным поиском для автоматизации подготовки ответов на запросы регуляторов.
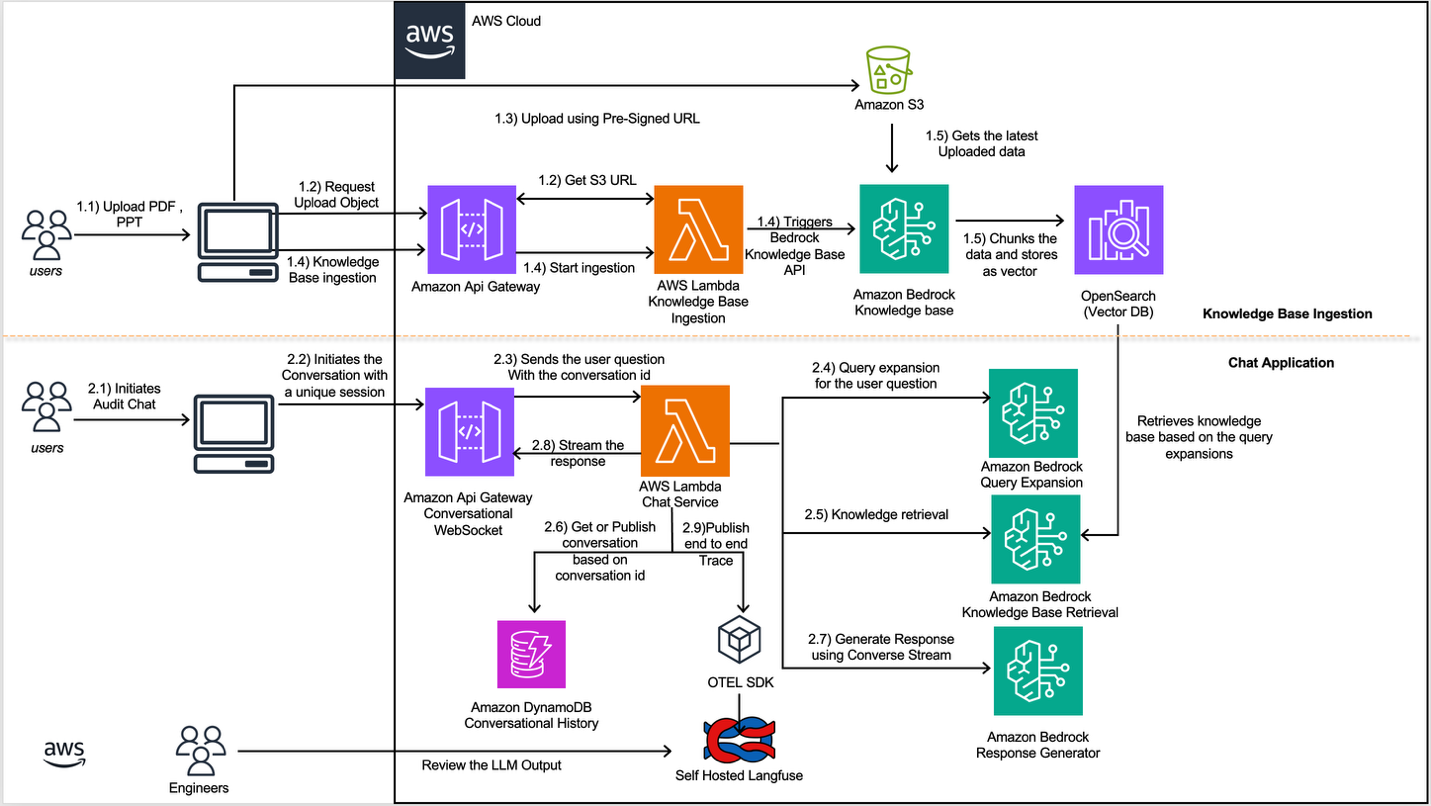
Amazon Finance развернула масштабируемое приложение на основе генеративного ИИ на AWS, чтобы автоматизировать ответы на регуляторные запросы и справляться с ростом обращений и усложнением требований разных юрисдикций. Решение использует Amazon Bedrock Knowledge Bases и Retrieval Augmented Generation (RAG) в сочетании с векторным поиском и чатом в реальном времени, что позволяет быстрее находить подтверждающие материалы и стандартизировать ответы. Это снизит нагрузку на команды и поможет поддерживать соответствие нормам в разных юрисдикциях.
Каждая доменная команда в Amazon Finance создает и поддерживает собственную базу знаний, заполненную её внутренними документами и справочными материалами, чтобы сохранять контекст и профильную экспертизу. Архитектура опирается на Amazon Bedrock Knowledge Bases и RAG для извлечения релевантной информации, Amazon OpenSearch Serverless как векторное хранилище, а за интерактивный чат отвечает Claude Sonnet 4.5 через Converse Stream API. Оркестрацию выполняют AWS Lambda, история диалогов хранится в Amazon DynamoDB, а процесс загрузки документов автоматизирован конвейером.
Пайплайн загрузки документов обрабатывает файлы разных форматов — PDF, PPT, Word, CSV-конвертирует содержимое в векторные эмбеддинги и индексирует их для поиска по тысячам исторических материалов. Система поддерживает пакетную загрузку и индексацию в Bedrock Knowledge Base, что ускоряет поиск прецедентов и подтверждающих доказательств при подготовке ответов регуляторам. Команда выделяет три основные сложности: фрагментация знаний и трудности поиска релевантных материалов между разными источниками, управление контекстом в многотуровых взаимодействиях с моделями и необходимость полной наблюдаемости работы генеративной модели. К ключевым рискам относятся галлюцинации моделей и использование устаревших нормативных правил, поэтому реализация требует трассируемости выбора источников и логики обнаружения ошибок.
Рост числа обращений и усложнение бизнес‑требований сделали ручные процессы непригодными: требовалось решение, масштабируемое по объему документов, поддерживающее разные форматы и обеспечивающее соблюдение требований в разных юрисдикциях. Подход с RAG и отдельными базами знаний для команд сочетает релевантность поиска с возможностью контроля доступа и ответственным использованием моделей. Для команд, которые строят аналогичные системы, отмечены практические рекомендации: использовать векторные хранилища и отдельные KB для каждой доменной команды, сохранять историю диалогов для поддержания контекста, интегрировать инструменты наблюдаемости вроде OpenTelemetry и self‑hosted Langfuse, не кэшировать результаты LLM при высокой контекстуальности запросов и организовать постоянный мониторинг точности и дрейфа моделей.
Источники
Ответы (0)
Пока нет ответов в этой теме.