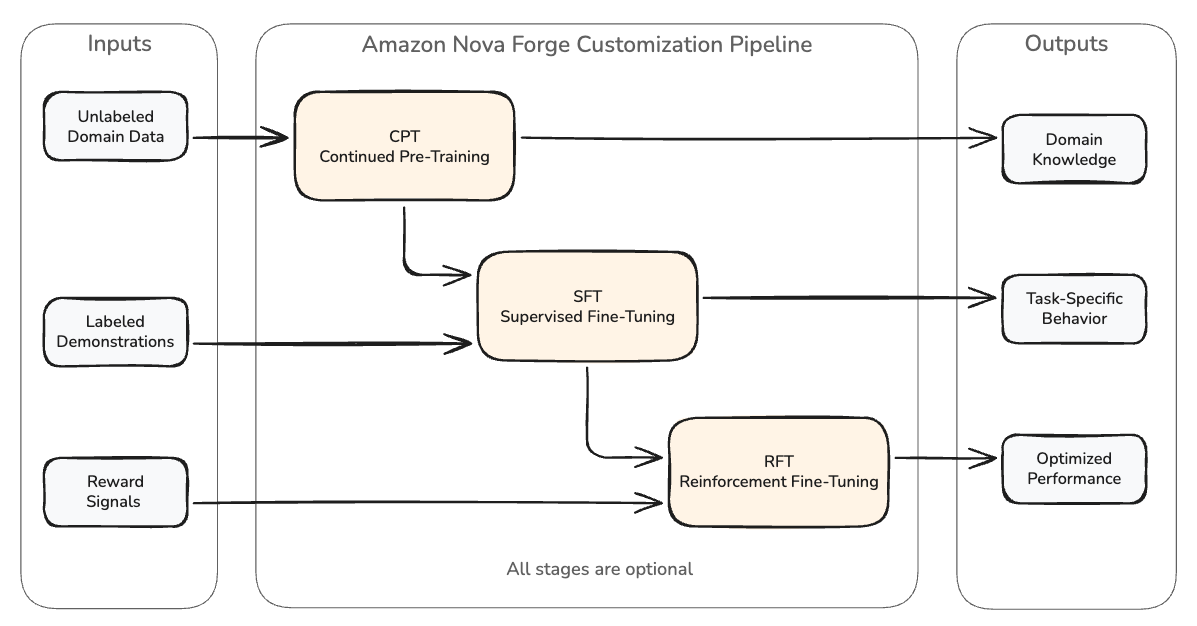
Amazon Nova Forge публикует практическое руководство по гиперпараметрической оптимизации при тонкой донастройке больших языковых моделей с целью повысить точность в узкой предметной области, не потеряв при этом общие языковые и инструкционные навыки. Это важно для команд, которые хотят доставить специализированные модели в продакшен быстрее и с меньшими рисками потери первоначального выравнивания и способностей модели. Платформа позволяет начинать разработку с ранних чекпоинтов Amazon Nova, смешивать приватные данные с отобранными учебными датасетами и затем безопасно хостить кастомные модели на AWS. Разработчикам даётся контроль над выбором чекпоинта и параметрами обучения, что помогает регулировать, сколько исходного выравнивания и предтренированных знаний сохраняется в процессе дообучения.
Ключевой механизм в подходе — «data mixing»: во время обучения пользовательские доменные данные комбинируются с кураторскими наборами, чтобы модель впитала специфическую информацию, но одновременно сохранила способность к обобщению, следованию инструкциям и языковым навыкам. Контроль над соотношением данных и выбором чекпоинта позволяет смещать баланс между специализацией и стабильностью моделей. Авторы выделяют три фундаментальные сложности настройки. Первая — катастрофическое забывание: при обучении на узких данных модель может утратить предтренированные общие навыки, снизив способность к рассуждению и поддержке многопетельных диалогов. В качестве иллюстрации приводят случай чат‑бота, дообученного на тикетах поддержки, который перестаёт корректно обрабатывать неоднозначные запросы и вести сложные диалоги.
Вторая проблема — чувствительность к скорости обучения. Скорость обучения — наиболее чувствительный гиперпараметр: слишком высокая вызывает «перепрыгивание» оптимума и быструю потерю базовых способностей, слишком низкая ведёт к неэффективному расходу вычислений и медленной сходимости. Nova Forge предлагает откалиброванные сервисные дефолты для каждой техники обучения; при использовании data mixing чувствительность к скорости возрастает, и отклонение от дефолтов часто приводит к нестабильности.
Третья группа рисков связана с взаимодействием параметров: соотношение данных, выбор чекпоинта, размер батча и способы чекпоинтинга могут тихо подрывать прогресс, если настраивать их по отдельности. В материале даются рекомендации по раннему обнаружению типичных ошибок и по метрикам, которые помогают балансировать между стабильностью и гибкостью модели. Практическое следствие для разработчиков — стартовать с сервисных дефолтов Nova Forge, использовать data mixing и тщательно контролировать метрики в первые эпохи, чтобы минимизировать риск деградации общих возможностей и потерь вычислительных ресурсов.
Источники
Ответы (0)
Пока нет ответов в этой теме.