AWS выпустила готовое событийно — ориентированное решение для автоматической синхронизации файлов между хранилищем Amazon S3 и базами знаний Amazon Bedrock, позволяющее эффективно обходить строгие квоты и ограничения API облачного сервиса
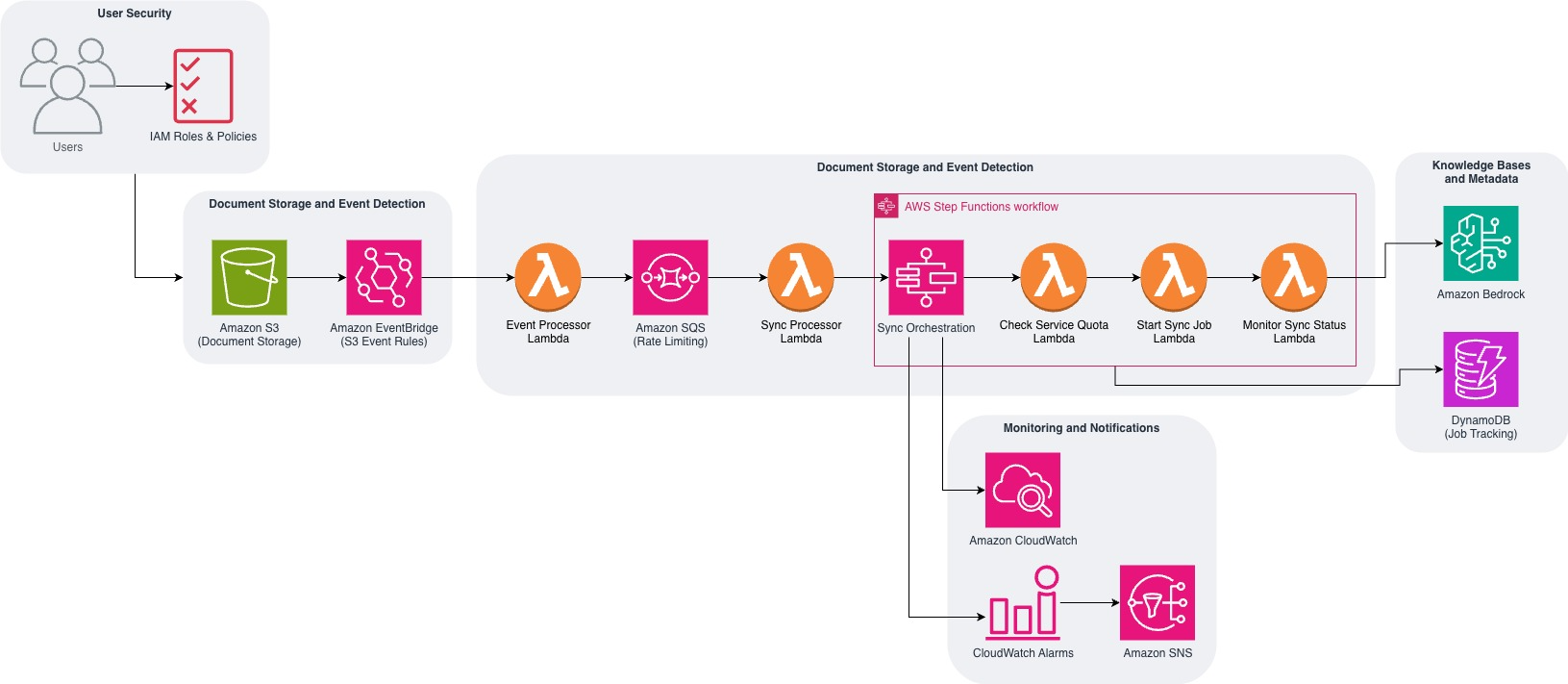
Компания Amazon Web Services представила детальное техническое руководство и готовую бессерверную архитектуру, предназначенную для автоматической синхронизации корпоративных документов между объектными облачными хранилищами Amazon Simple Storage Service и базами знаний Amazon Bedrock Knowledge Bases. Использование баз знаний позволяет предоставлять базовым моделям искусственного интеллекта и интеллектуальным агентам необходимую контекстную информацию из закрытых частных источников данных организации. Это критически важно для формирования релевантных, точных и индивидуально настроенных ответов.
Основная сложность внедрения подобных систем заключается в том, что базы знаний в Amazon Bedrock традиционно требуют выполнения ручной синхронизации каждый раз, когда документы или связанные с ними файлы метаданных добавляются, изменяются или удаляются в целевой корзине облачного хранилища. Организациям жизненно необходима автоматизированная синхронизация для поддержки сред с частыми обновлениями контента и многопользовательских систем, где различные команды загружают новые файлы на протяжении всего рабочего дня. Кроме того, автоматизация абсолютно критична для приложений, работающих в режиме реального времени, таких как системы поддержки клиентов, которым требуется немедленный доступ к самой свежей справочной информации.
Для достижения надежной автоматизации инженерам необходимо тщательно оркестровать операции синхронизации, строго соблюдая защитные ограничения и квоты сервисов платформы Amazon Bedrock. На данный момент облачный провайдер установил жесткие лимиты на параллельные задачи по приему данных: разрешается выполнять не более пяти задач на один аккаунт AWS, что помогает предотвратить случайное исчерпание вычислительных ресурсов. Дополнительно допускается только одна активная задача на конкретную базу знаний для обеспечения сфокусированной обработки, а также строго одна задача на отдельный источник данных для поддержания общей согласованности информации.
Помимо ограничений на количество одновременных задач, проектируемая система должна учитывать строгие лимиты частоты отправляемых запросов. Программный интерфейс старта синхронизации для баз знаний имеет ограничение скорости в одну десятую запроса в секунду, что эквивалентно всего одному обращению каждые десять секунд в каждом регионе. В качестве примера можно рассмотреть ситуацию, когда команда по работе с контентом обновляет сразу несколько файлов во время выпуска нового релиза. Без скоординированного подхода программные запросы неизбежно выстроятся в очередь из-за системных ограничений, что потребует ручного контроля.
Предложенное событийно — ориентированное решение автоматически отслеживает изменения в корзинах хранения и использует оптимизированную модель развертывания облачных приложений, функционируя как полностью бессерверная система без необходимости управления базовой инфраструктурой. Архитектура объединяет несколько ключевых управляемых сервисов для обработки файловых операций в режиме реального времени. Начальная фаза работы системы заключается в автоматическом обнаружении изменений: когда документы загружаются, модифицируются или удаляются, хранилище автоматически генерирует системные события. Эти данные моментально перехватываются специализированным маршрутизатором Amazon EventBridge, который выступает в роли центрального диспетчера для запуска всей последующей цепочки обработки.
После перехвата события маршрутизатор последовательно запускает бессерверные вычислительные функции AWS Lambda, которые отвечают за непосредственную обработку системных уведомлений и управление конвейером синхронизации. Вызванная функция извлекает важнейшие метаданные документа, включая точный путь к целевому файлу, тип произошедшего изменения и временную метку события. Полученная информация затем используется для создания подробных записей отслеживания в нереляционной базе данных Amazon DynamoDB. Это обеспечивает надежный аудиторский след для всех файловых операций и сохраняет метаданные запущенных задач, формируя прозрачную историю обновления базы знаний.
Сразу после фиксации метаданных вычислительная функция отправляет сообщение с запросом на синхронизацию в сервис очередей Amazon Simple Queue Service. Использование этих очередей позволяет безопасно буферизировать поступающие запросы, грамотно управлять ограничениями скорости и обеспечивать надежную доставку данных без превышения установленных лимитов платформы. За общую оркестрацию всего сложного рабочего процесса отвечает сервис AWS Step Functions, координирующий действия разрозненных компонентов.
Источники
Ответы (0)
Пока нет ответов в этой теме.