В условиях стремительного развития искусственного интеллекта, большие языковые модели (LLM) стали движущей силой для передовых разговорных агентов, инструментов для творчества и систем поддержки принятия решений. Однако их изначальный вывод часто содержит неточности, несоответствия установленным политикам или нежелательные формулировки, что подрывает доверие и ограничивает их практическую ценность в реальных сценариях. В ответ на эти вызовы, Reinforcement Fine — Tuning (RFT) стал предпочтительным методом для эффективной настройки этих моделей, используя автоматизированные сигналы вознаграждения вместо дорогостоящей ручной разметки.
Подход RLAIF, использующий LLM в качестве судьи, предоставляет значительно большую гибкость и мощь по сравнению с общим RFT, особенно когда сигналы вознаграждения являются расплывчатыми и трудно формулируются вручную. В отличие от общих наград RFT, которые полагаются на простые числовые оценки, такие как сопоставление подстрок, LLM-судья способен рассуждать по множеству измерений, включая корректность, тон, безопасность и релевантность. Это позволяет ему предоставлять контекстно — ориентированную обратную связь, которая улавливает тонкости и нюансы предметной области без необходимости переобучения для конкретной задачи.
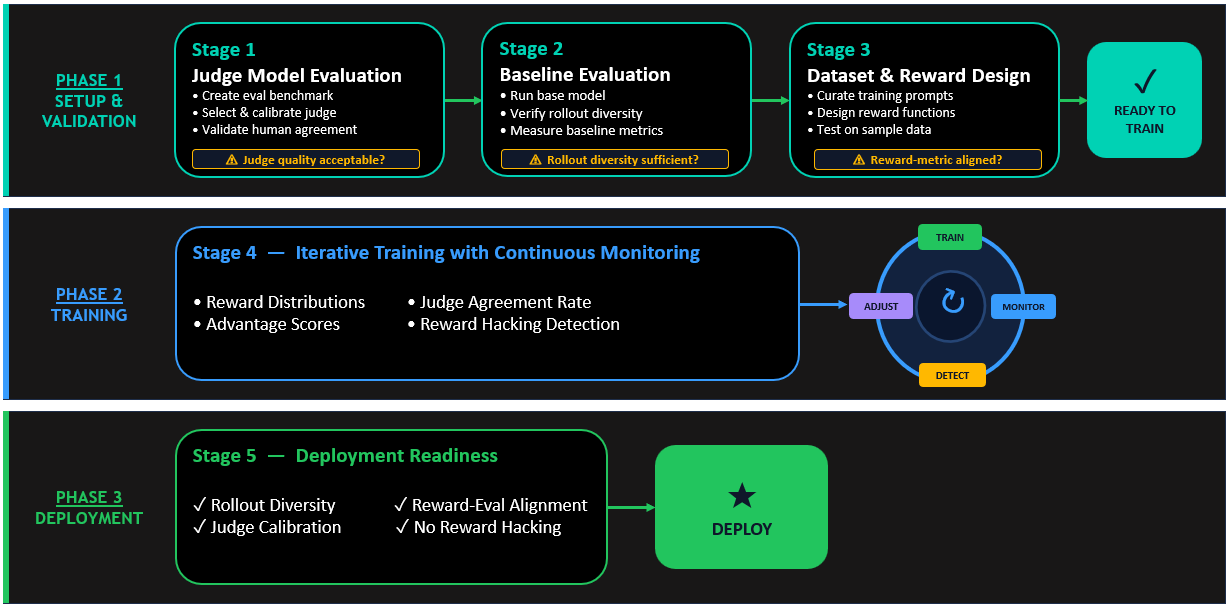
Реализация LLM-as-a-judge включает в себя несколько критически важных шагов, первым из которых является выбор архитектуры судьи. Существует два основных режима оценки: судейство на основе рубрик (Rubric — based judging) и судейство на основе предпочтений (Preference — based judging). Судейство на основе рубрик присваивает числовую оценку одному ответу, используя предопределенные критерии, что подходит для случаев, когда существуют четкие, измеримые параметры оценки, такие как точность или полнота. Этот метод обеспечивает абсолютные измерения качества и часто является хорошей отправной точкой при отсутствии данных о предпочтениях. Судейство на основе предпочтений, напротив, сравнивает два кандидата ответа и выбирает лучший, что отражает естественную человеческую оценку через сравнение.
После выбора типа судьи критически важно определить конкретные критерии оценки, которые должны быть улучшены. Для судей на основе предпочтений необходимо создать четкие подсказки, объясняющие, что делает один ответ лучше другого, с конкретными примерами, такими как предпочтение ответов, цитирующих авторитетные источники, использующих доступный язык и непосредственно отвечающих на вопрос пользователя. Для судей на основе рубрик рекомендуется использовать булеву (прошел/не прошел) оценку, так как она более надежна и снижает изменчивость оценок по сравнению с более тонкими шкалами. Следующий шаг — выбор и настройка модели судьи, которая должна обладать достаточными возможностями рассуждения для оценки в целевой области.
Последний, но не менее важный шаг — это уточнение промпта для модели судьи. Промпт является основой качества выравнивания и должен быть разработан таким образом, чтобы производить структурированные, легко анализируемые выходы с четкими измерениями оценки, например, в формате JSON. Эти системные подходы к разработке и развертыванию функций вознаграждения LLM-as-a-judge в конечном итоге способствуют созданию более надёжных, точных и соответствующих политике LLM. Это позволяет AI-системам лучше справляться с проблемами, которые ранее подрывали доверие и ограничивали практическую ценность, открывая путь к их более широкому и безопасному применению в различных сферах человеческой деятельности.
Источники
Ответы (0)
Пока нет ответов в этой теме.