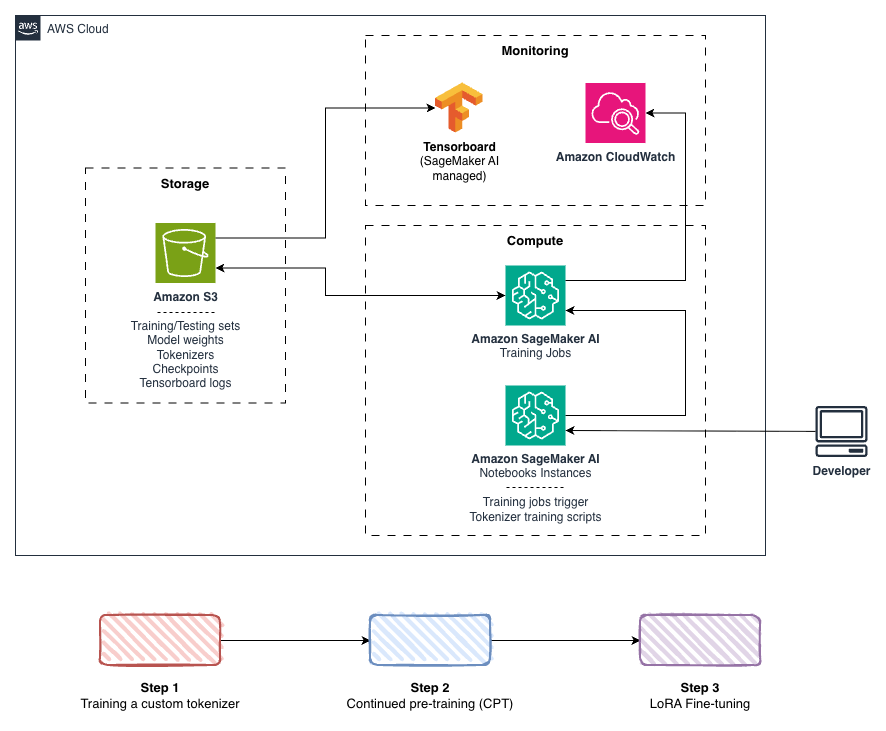
Azercell Telecom совместно с AWS Generative AI Innovation Center за шесть недель разработали production‑ready фреймворк на Amazon SageMaker AI для обучения азербайджанской большой языковой модели (LLM) и клиентского чат‑ассистента, решив ключевые проблемы — морфологическую сложность языка и дефицит размеченных данных. Этот результат важен для команд, работающих с малоресурсными или морфологически насыщенными языками, поскольку предлагает проверенную практическую дорожную карту от токенизации до диалогового файнтюнинга.
Фреймворк включает три последовательных этапа: разработку токенайзера, continued pre‑training (CPT) на базе Llama 3.2 1B и supervised fine‑tuning с использованием Low‑Rank Adaptation (LoRA). Для CPT применялись распределённое обучение и оптимизации на уровне ядер (Liger Kernels), а LoRA использовали как параметро‑эффективный метод перевода модели в режим диалога и сокращения затрат на дообучение. Тренировки запускались как Amazon SageMaker AI training jobs из SageMaker Unified Studio с пользовательскими скриптами: каждое задание создаёт отдельные Amazon EC2‑инстансы, завершает их по окончании работы и тем самым исключает простой кластеров и оплату простаивающих ресурсов. Данные и артефакты сохранялись в Amazon S3, метрики обучения — в TensorBoard, а системные метрики собирались через Amazon CloudWatch.
Работа над токенайзером учитывала морфологическую насыщенность азербайджанского: стандартные токенайзеры, оптимизированные под английский, дробят сложные формы (пример — «kitablardan»), что уменьшает полезный контекст. Авторы сравнили три подхода — базовый англоязычный токенайзер, расширение словаря и монолингвальный кастомный токенайзер — и показали, что кастомный токенайзер дал наилучший эффект, сокращая количество токенов на слово примерно вдвое. Оптимизации Liger Kernels и выбранные конфигурации CPT позволили увеличить размер батчей и повысить пропускную способность без смены железа: при тестах на инстансе ml.p5.48xlarge зафиксирован рост throughput на 23% и снижение пикового использования GPU‑памяти на 58%. Такие улучшения упрощают перенос конфигураций CPT в последующие задачи файнтюнинга и уменьшают потребность в более дорогом оборудовании на ранних этапах экспериментов.
Авторы подчёркивают, что для 1B‑масштаба прототипа распределённое обучение не было обязательным, но станет критичным при масштабировании на большие модели. Публикация предлагает разработчикам практическое руководство по использованию PyTorch, Hugging Face Transformers и Liger Kernels внутри Amazon SageMaker AI для оценки токенизации, проведения CPT и параметро‑эффективного LoRA‑файнтюнинга.
Источники
Ответы (0)
Пока нет ответов в этой теме.