Artificial Analysis и IBM Research 27 мая 2026 года выпустили ITBench — AA, пилотный бенчмарк для оценки агентных моделей в корпоративных IT‑операциях; в первых SRE‑тестах ни одна фронтирная модель не сумела превысить 50% по объявленной метрике, что ставит под вопрос готовность таких агентов к самостоятельной диагностике инцидентов. Это важно для команд Site Reliability Engineering: низкие показатели по полноте обнаружения означают риск пропуска корневых причин при автоматизированной обработке инцидентов и необходимость доработки моделей перед боевым использованием.
Набор SRE‑задач включает 59 инцидентов — 40 публичных и 19 закрытых (held‑out). Каждая задача поставляет снимок Kubernetes‑инцидента со связкой оповещений, событий, трассировок, метрик, логов и топологией приложения; агенты запускаются в справочном харнесе Stirrup и имеют доступ к песочнице с файлами. В качестве ответа система требует минимальный набор независимых корневых сущностей Kubernetes, ответственных за инцидент, что имитирует практическую потребность SRE-выделить конкретные ресурсы или компоненты для устранения.
Методология фиксирует харнес Stirrup и лимит в 100 ходов на задачу с тремя повторами. Оценка строится на average precision при условии полного покрытия: если агент пропускает любую корневую компоненту (recall < 100%) — для этого прогона ставят 0; при полном покрытии итоговый балл прогона равен precision (TP/(TP+FP)). Финальный показатель по набору — среднее значение по 59 задачам и трём повторениям, что жёстко штрафует неполные решения.
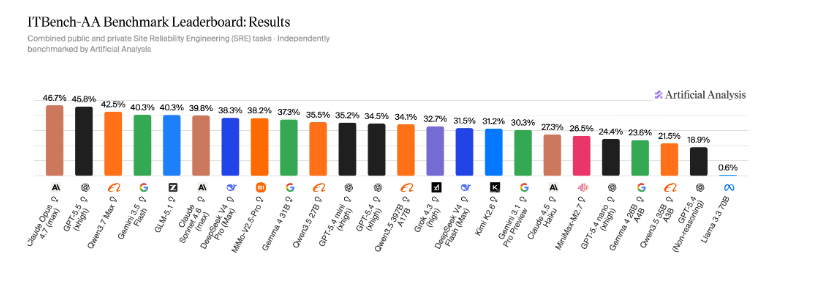
По результатам лидерство у Claude Opus 4.7 (Adaptive Reasoning, Max Effort) — 47%, за ним GPT‑5.5 (xhigh) — 46% и Qwen3.7 Max-42%; ни одна фронтирная модель не превысила порог в 50%, поэтому ITBench — AA SRE оказался одним из наименее насыщенных агентных бенчмарков в наборе тестов (авторы при этом отмечают, что на другом бенчмарке — Terminal — Bench — фронтирные модели показывают значительно более высокие значения).
Анализ поведения агентов выявил почти трёхкратную вариацию числа ходов между моделями: GPT‑5.5 в среднем делает 31 ход при 46% точности, тогда как Gemini 3.1 Pro Preview требует около 83 ходов при 30% точности. Модели, склонные к чрезмерному расследованию, чаще фиксируют ложные срабатывания, ошибочно принимая механизмы инъекции неисправностей или смежные симптомы за корневые причины. Среди открытых моделей лидирует GLM‑5.1 (Reasoning) — 40%, сравнимый уровень у Gemini 3.5 Flash (high); далее DeepSeek V4 Pro-38% и Gemma 4 31B-37%.
Датасет разработан IBM Research на базе опыта в корпоративных операциях, а Artificial Analysis формализовала его в тестовый формат в последние шесть месяцев. Задачи имитируют типичные SRE‑сбои — исчерпание квот ресурсов, ошибки rollout, исчерпание connection pool, сетевые разрывы и инъекции хаоса. Авторы планируют расширять серию на FinOps и CISO‑задачи; текущие результаты подчёркивают необходимость дальнейшей работы по повышению полноты обнаружения и сокращению ложных позитивов, прежде чем агентные средства станут надёжным инструментом для оперативной диагностики.
Источники
Ответы (0)
Пока нет ответов в этой теме.