LangSmith выпустил практическое руководство по валидации глубоких агентов в сочетании с инструментами AWS, объясняя, как перейти от разработки к продакшену. Документ объединяет наработки LangChain и рекомендации Anthropic, показывает конкретные приёмы оценки и мониторинга и иллюстрирует их на примере text‑to‑SQL агента; одним из соавторов материала указан Karan Singh, Head of Partnerships в LangChain. Это важно для команд, которые сталкиваются с нестабильностью результатов и сложностями отладки многошаговых агентов в боевой эксплуатации.
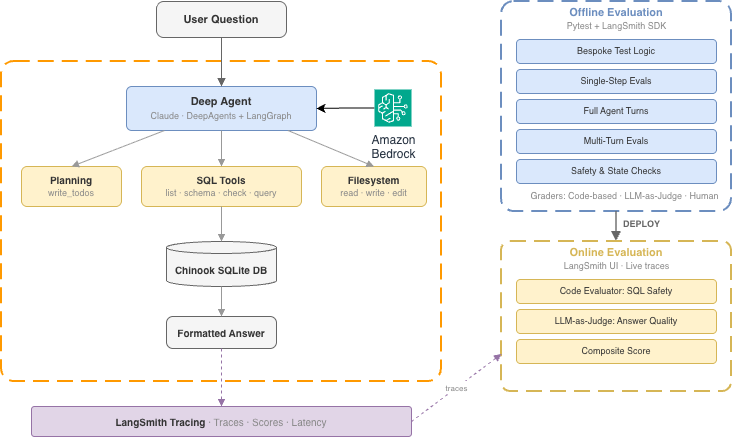
Авторы описывают три ключевых шага рабочего процесса: применение пяти паттернов оценки глубоких агентов, построение офлайн‑оценок с pytest и LangSmith и настройка онлайн‑мониторинга в продакшне. Walkthrough показывает, как связать эти этапы в единую цепочку валидации — от формализации задач до непрерывного наблюдения — чтобы быстрее находить и воспроизводить ошибки. В демонстрации используется Amazon Bedrock и модель Amazon Nova 2 Lite; модель позиционируется как быстрая и экономичная для рассуждений с настраиваемыми уровнями бюджета (low, medium, high). Отмечены её возможности принимать текст, изображения, видео и документы и поддерживать контекстное окно до 1 миллиона токенов, что важно для сложных multi‑step сценариев и тестов с большими рабочими контекстами.
Материал выделяет ключевые трудности оценки агентных систем: недетерминированность выводов, каскадирование ошибок в многошаговых потоках и появление неожиданных, но корректных решений. Для учёта недетерминированности рекомендуется запускать несколько trial‑ов и применять метрики pass@k (вероятность хотя бы одного успеха в k попытках) и pass^k (вероятность успеха во всех k попытках); выбор метрики зависит от того, требуется ли одноразовый успех или согласованность результатов между попытками.
Документ вводит базовую терминологию и инфраструктуру оценки: task (отдельный тест с входом и критерием успеха), trial (отдельная попытка), grader (логика оценки), transcript (полная запись шагов), outcome (итоговое состояние среды), evaluation harness (инфраструктура запуска) и evaluation suite (набор задач). LangSmith хранит полные транскрипты для отладки, позволяет инспектировать вызовы инструментов и агрегировать метрики, что облегчает поиск причин ошибок и анализ поведения агента.
Практические рекомендации для разработчиков включают проектирование graders, покрывающих разные измерения (траекторию вызовов инструментов, корректность финального ответа и соответствие outcome), интеграцию офлайн‑тестов с pytest и LangSmith в CI и настройку онлайн‑мониторинга для ловли редких и каскадных ошибок в продакшне. В случае text‑to‑SQL особенно важно отслеживать ранние шаги, например идентификацию схемы: ошибка на этапе распознавания структуры БД может привести к некорректным JOIN‑ам и, как следствие, неверным итоговым ответам.
Источники
Ответы (0)
Пока нет ответов в этой теме.