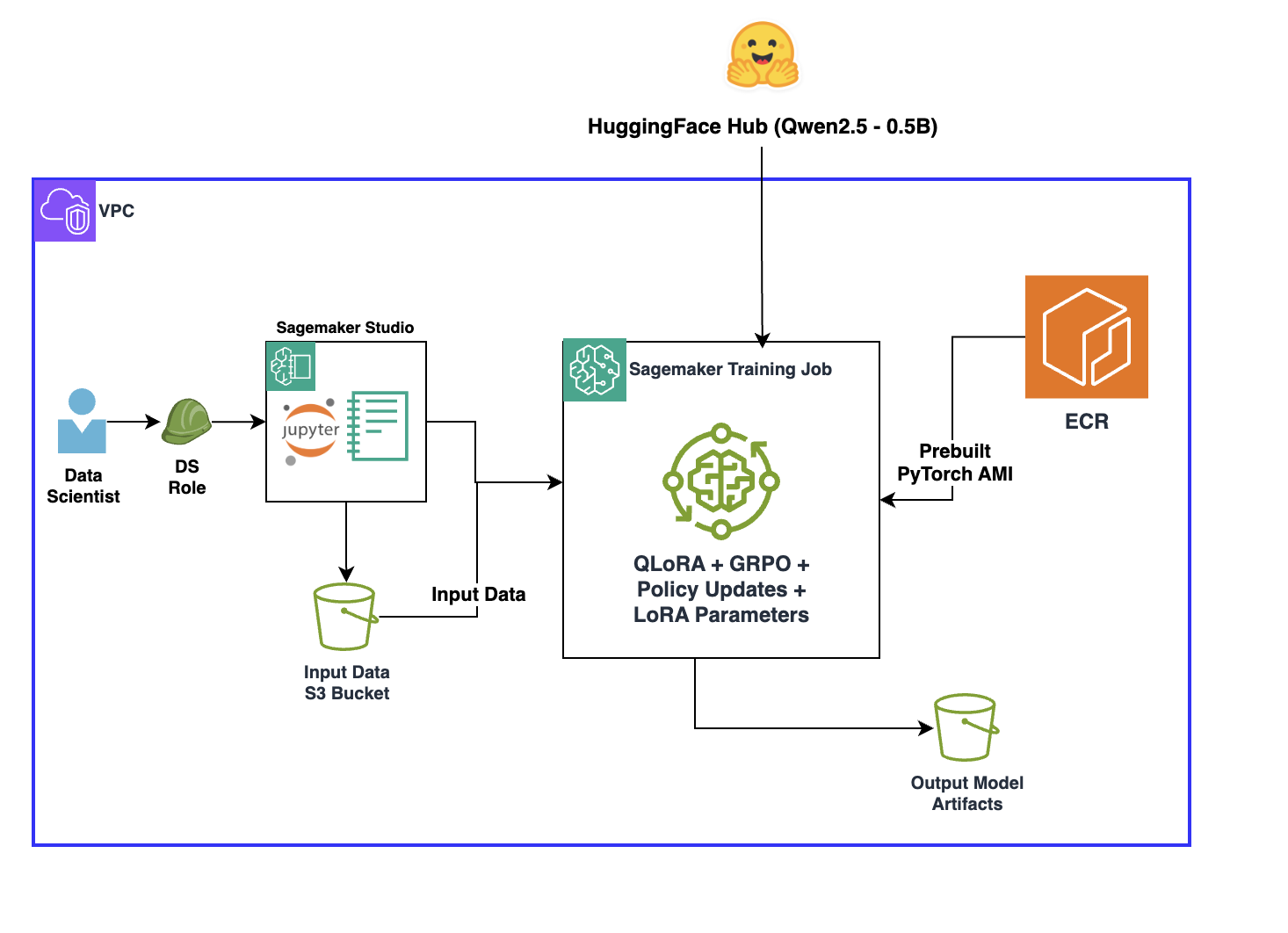
Авторы представляют reinforcement learning with verifiable rewards (RLVR) — метод, в котором часть человеческой оценки заменяют программными, проверяемыми функциями вознаграждения, и демонстрируют его работу вместе с Group Relative Policy Optimization (GRPO) и few‑shot примерами на платформе SageMaker AI. Такой подход призван повысить прозрачность и надёжность сигналов вознаграждения при обучении моделей, что важно для ускорения итераций и снижения затрат на аннотацию данных.
Технически RLVR опирается на программные функции вознаграждения, которые тюнер модели определяет заранее и которые автоматически сравнивают ответы модели с объективными критериями. Метод показан в связке с GRPO и few‑shot примерами для тренировки политик, а качество решений проверяли на датасете GSM8K (Grade School Math 8K) — наборе школьных математических задач, пригодных для объективной оценки правильности. Авторы обращают внимание на проблемы традиционных подходов RL: ненадёжные сигналы, скрытые смещения, неоднозначность критериев успеха и риск «reward hacking», когда модель находит обходные способы максимизации вознаграждения. RLVR снижает эти риски за счёт воспроизводимости правил и автоматической оценки, уменьшая зависимость от дорогостоящих и вариативных человеческих оценок.
Практическое значение метода состоит в том, что он особенно применим к задачам с объективно проверяемыми ответами — например, математике, генерации кода и символическим преобразованиям — и даёт путь для быстрого прототипирования и адаптации политик. Реализация на SageMaker AI предоставляет инженерам воспроизводимую инфраструктуру для экспериментов и создаёт предпосылки для масштабирования подхода на другие прикладные сценарии.
Источники
Ответы (0)
Пока нет ответов в этой теме.