В демонстрации представлено решение для комплексной наблюдаемости LLM‑инференса на SageMaker AI endpoints с использованием Managed Grafana, объединяющее операционные и качественные сигналы в одной панели. Такой подход важен для команд, которые отвечают за продакшен‑инференс: единой визуализации достаточно, чтобы одновременно отслеживать стабильность сервиса и оценивать качество вывода моделей, что снижает риск незаметных деградаций при нормальных инфраструктурных показателях.
Авторы разделяют наблюдаемость на две взаимодополняющие области — «количество» (quantity) и «качество» (quality). К «количеству» относятся метрики пропускной способности: счётчики вызовов (invocation counts), задержки (latency), ошибки (error rates) и использование ресурсов (GPU/CPU/память). К «качеству» относятся метрики точности ответов, соответствия политикам и согласованности во времени; качество фиксируется через выборку выводов и вычисление пользовательских quality‑метрик для обнаружения дрейфа и непредсказуемого поведения моделей.
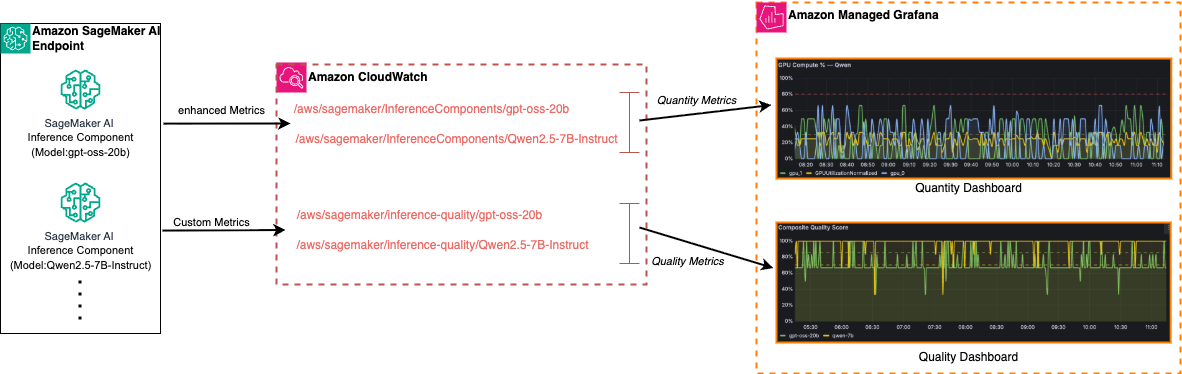
В основе демонстрационной архитектуры — inference components в SageMaker AI: один endpoint может хостить несколько компонентов (например, gpt‑oss‑20b и Qwen2.5‑7B‑Instruct), что обеспечивает изоляцию для маршрутизации трафика, правил масштабирования и атрибуции метрик. Такое разделение упрощает сравнение моделей и тестирование конфигураций, одновременно помогая решать операционные задачи: непредсказуемое потребление токенов, давление на GPU‑память и всплески задержек влияют на планирование ёмкости и контроль затрат, а деградации качества не всегда отражаются в инфраструктурных показателях.
Сбор и визуализация данных опираются на три сервиса: endpoints с inference components, CloudWatch и Managed Grafana. SageMaker автоматически публикует enhanced metrics при их включении в конфигурации endpoint; эти метрики доступны на уровнях инстанса, контейнера и каждого GPU и включают invocation counts, latency, error rates и CPU/GPU utilization. Метрики логируются в namespace /aws/sagemaker/InferenceComponents/ (пример: /aws/sagemaker/InferenceComponents/gpt‑oss‑20b). сначала вводят видимость базовых операционных сигналов, затем добавляют выборку выводов и расчёт quality‑метрик, после — пороговые оповещения, автоматизацию и сравнительный анализ конфигураций для оптимизации затрат, производительности и качества.
Источники
Ответы (0)
Пока нет ответов в этой теме.