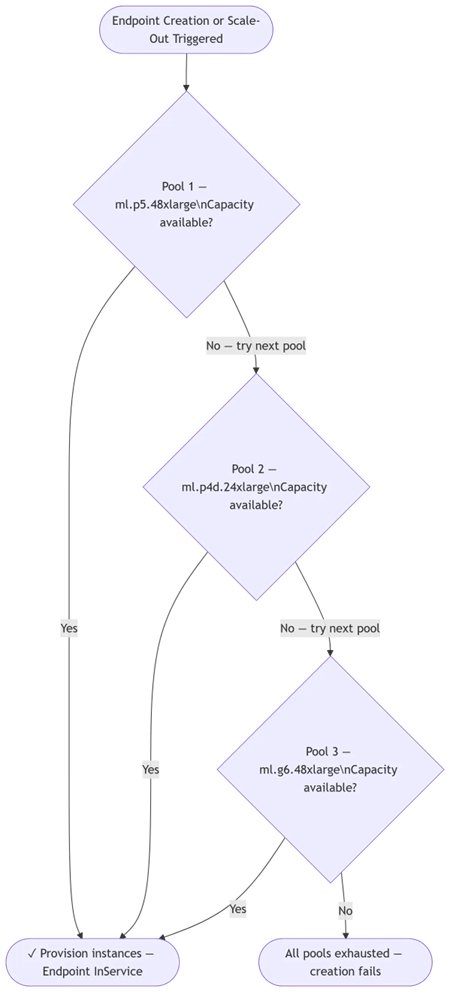
SageMaker AI представил возможность конфигурировать capacity‑aware instance pools — приоритетные пул‑наборы типов инстансов для inference‑эндпоинтов. В настройках эндпоинта задаётся ранжированный список InstanceType; если предпочитаемый тип недоступен, платформа последовательно пробует следующий вариант, позволяя точке выдачи выйти в состояние InService без ручной смены конфигурации. Механизм призван уменьшить блокировки развёртывания, когда конкретный тип инстанса временно исчерпан. Механика охватывает три ключевые этапа жизненного цикла эндпоинта. При создании платформа сначала пытается запустить указанный в приоритете тип и при его отсутствии автоматически переключается на следующий в списке; при масштабировании scale‑out, если предпочтительный тип исчерпан, новые узлы добавляются из следующего доступного типа; при scale‑in первыми удаляются инстансы с наименьшим приоритетом, что со временем возвращает флот к предпочитаемому железу.
До появления этой функции развёртывание с фиксированным типом могло завершаться ошибкой Insufficient Capacity, а автомасштабирование повторно пробовало тот же недоступный тип, тормозя рост кластера. Параллельно расширена наблюдаемость: существующие метрики теперь получают измерение InstanceType в Amazon CloudWatch, что позволяет разбивать задержки, пропускную способность, загрузку GPU и количество инстансов по типам внутри одного эндпоинта. Это упрощает отладку проблем с производительностью и помогает локализовать аппаратные узкие места без отдельного развёртывания тестовых конфигураций.
Инженерам и владельцам моделей важно учитывать, что fallback‑типы могут существенно отличаться по объёму памяти GPU, числу ядер и архитектуре, поэтому модель, оптимизированная под high‑memory или многопроцессорные GPU‑инстансы, может иначе вести себя на менее ёмком резерве. При проектировании pool стоит ранжировать типы с учётом требований к памяти, числу GPU и пропускной способности, а также тестировать поведение модели на каждом кандидате. Практические выгоды включают снижение числа отказов при создании эндпоинтов, более плавное масштабирование при пиковых нагрузках и сокращение ручных переборов типов.
Платформа обещает, что эндпоинты выйдут в InService на первой доступной инфраструктуре «в течение минут», а метрики по типам инстансов помогут принимать решения по миграции и оптимизации флота. Для технических деталей и примеров реализованных конфигураций доступны документация SageMaker AI и примерная тетрадь (notebook) на GitHub; исходная заметка о нововведении опубликована в блоге с подробным разбором реализации.
Источники
Ответы (0)
Пока нет ответов в этой теме.