Strands Evals ввёл четыре мультимодальных оценщика — Overall Quality, Correctness, Faithfulness и Instruction Following — которые оценивают ответы на основе самого изображения и могут работать в CI‑конвейерах для автоматического выявления визуальных ошибок.
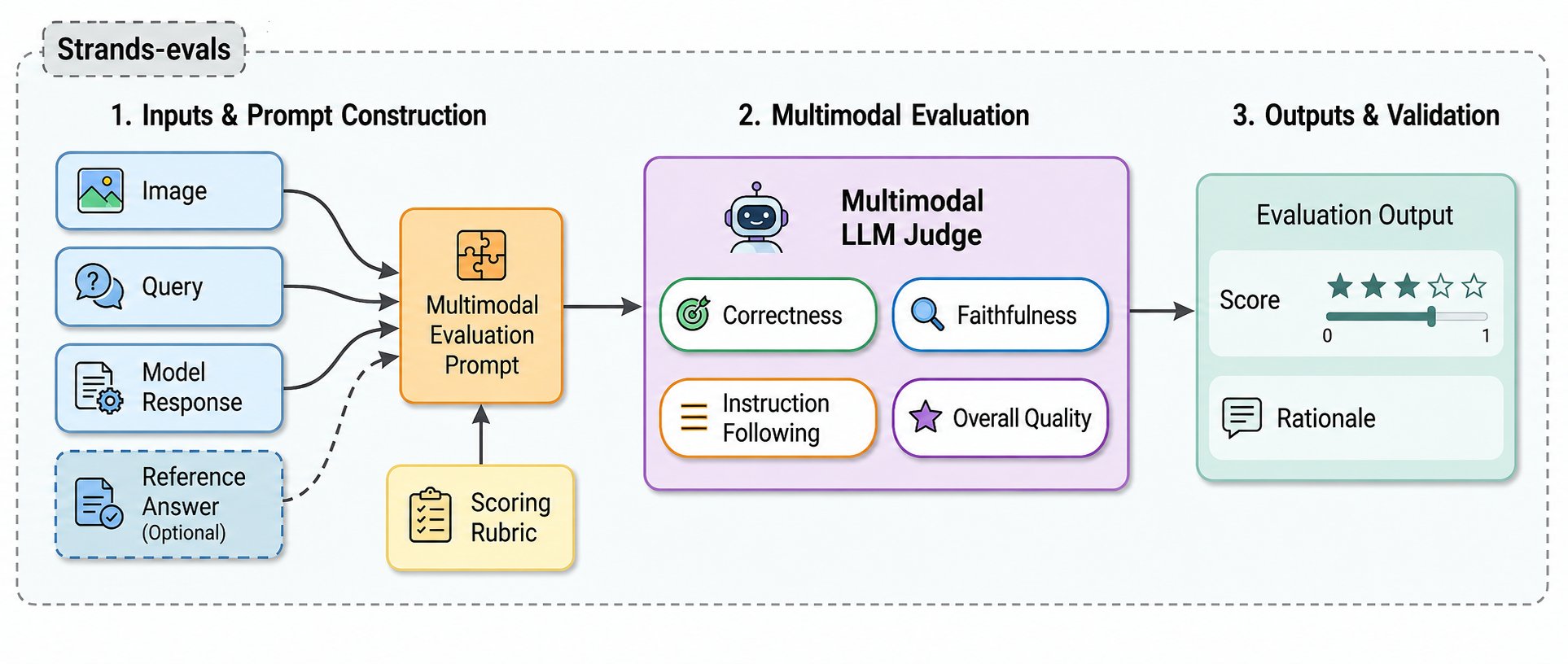
Strands Evals представил четыре мультимодальных оценщика (MLLM‑as‑a‑Judge) для задач преобразования изображения в текст: Overall Quality, Correctness, Faithfulness и Instruction Following. Оценщики анализируют не только текстовый вывод модели, но и содержимое изображения, что позволяет выявлять визуальные галлюцинации и иные ошибки, которые остаются незаметными для текст‑только судей. Это важно для разработчиков, которым нужно автоматизировать проверку визуально‑зависимых систем и встраивать её в CI‑процессы.
Каждый оценщик получает на вход изображение вместе с запросом и ответом модели; опционально можно передать эталонный ответ. Фреймворк напрямую направляет изображение мультимодальной модели‑судье вместе с контекстом и возвращает либо шкалу Лайкерта (1–5), либо бинарную метрику и строку с развёрнутым рассуждением для отладки. Развёрнутые объяснения помогают понять причину низкой оценки и ускоряют исправление ошибок. Оценщики можно использовать вместо текст‑только судей в существующем рабочем цикле Case → Experiment → Report в Strands Evals и подключать к конвейерам CI для автоматического выявления визуальных галлюцинаций, фактических ошибок и нарушений инструкций. Интеграция в отчётность и CI облегчает обнаружение регрессий при обновлении моделей и приёмке релизов.
Авторы описывают настройки: один и тот же оценщик можно переключать между reference‑based и reference‑free режимами, можно написать кастомную мультимодальную рубрику под предметно‑ориентированные требования, а выбор модели‑судьи на Amazon Bedrock делается с учётом баланса точности, стоимости и задержки. В посте также приведены экспериментальные подсказки, которые улучшали согласование с человеческими оценками, то есть подбор промптов остаётся важным фактором. Команда объясняет, почему текст‑только оценщики не подходят для визуальных задач: они не видят изображение и могут пропустить ключевые ошибки — например, ошибочную интерпретацию тренда на графике, выдумку товара или метки, либо неверный формат ответа. Один общий балл затрудняет отладку, поскольку разные типы ошибок требуют разных исправлений; четыре специализированных оценщика адресуют отдельные режимы сбоев.
Для воспроизведения и тестирования нового функционала требуются Python 3.10 или новее и установка пакетов: pip install strands‑agents‑evals для оценщиков и pip install strands‑agents для агента из примера. Также необходим аккаунт с доступом к Amazon Bedrock и локально сконфигурированные AWS‑учётные данные (или роль IAM) с правом InvokeModel для выбранной модели‑судьи, а также знание базового рабочего цикла Strands Evals.
Это решение имеет прикладное значение на фоне роста мультимодальности: по прогнозу Gartner к 2030 году около 80% корпоративного ПО станет мультимодальным против менее 10% в 2024 году. Без автоматизированной мультимодальной оценки разработчики остаются между дорогостоящей ручной проверкой и ненадёжными текстовыми прокси; встроенные MLLM‑оценщики в CI и отчётности помогают масштабировать контроль качества визуально‑зависимых систем.
Источники
Ответы (0)
Пока нет ответов в этой теме.