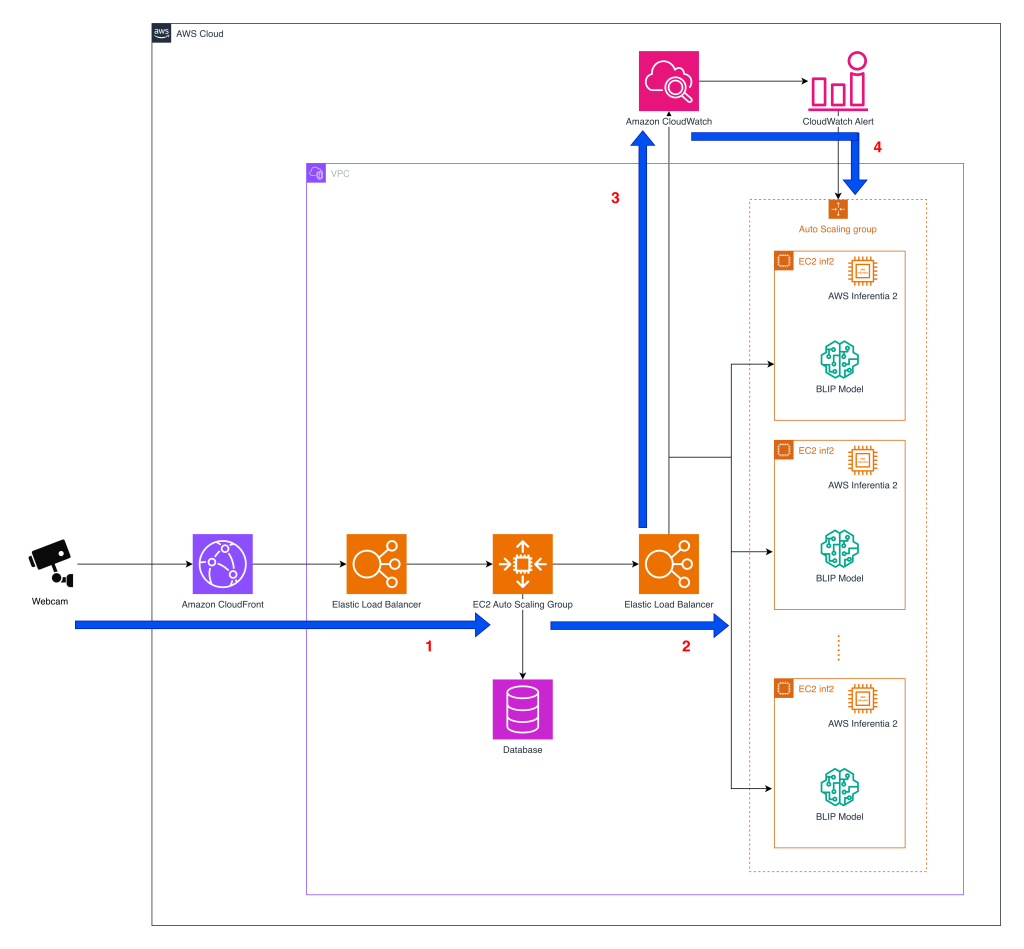
Tomofun, разработчик камеры Furbo, перевёл реализацию инференса визуально‑языковой модели в облаке на инстансы EC2 Inf2 на базе AWS Inferentia2 в попытке снизить затраты при круглосуточном мониторинге питомцев. В основе новой архитектуры — двухслойная схема: входящие видеопотоки проходят через Amazon CloudFront и Elastic Load Balancing (ELB) и попадают сначала на API‑слой в Auto Scaling, а затем — на отдельную Auto Scaling‑группу, выделенную под инференс. Поток с устройств маршрутизуется к API‑серверу первого уровня, где выполняется предварительная обработка кадра; после этого изображение перенаправляется во второй уровень, где в контейнерах запускаются модели инференса. Разделение бизнес‑логики API и вычислительных задач позволяет изолировать тяжёлые операции распознавания от сервисной части и гибко масштабировать именно инференс‑флот.
Ранее инференс выполнялся на GPU‑инстансах Amazon EC2: это давало высокую пропускную способность, но было экономически невыгодно для сценария «всегда‑включено». Новое решение размещает контейнеры с компонентами BLIP (Bootstrapping Language‑Image Pre‑Training), скомпилированными с помощью Neuron SDK, чтобы они могли работать на EC2 Inf2 с AWS Inferentia2. Вызовы API при этом могут направляться либо в GPU‑контейнеры, либо в Inf2‑контейнеры без изменений во внешнем API и в логике оповещений. Главная техническая задача заключалась в сохранении качества детекции поведения животных — лай, бег, необычная активность — при постоянном инференсе для сотен тысяч устройств, не переписывая полностью код BLIP, оптимизированный под PyTorch.
Для наблюдаемости и обеспечения SLO Amazon CloudWatch собирает метрики инференс‑флота: задержки, пропускную способность и ошибки. ELB распределяет запросы по доступным инстансам, а Auto Scaling изменяет размер пула в зависимости от реального числа входящих запросов; решения о масштабировании опираются на предварительные стресс‑тесты и измерения пропускной способности для каждого типа инстанса. Практический эффект для Furbo — возможность в реальном времени переключать бэкенды инференса между GPU и Inferentia2, сохраняя тот же API и поведение уведомлений.
Этот опыт служит прикладным примером для инженеров и архитекторов: собрать контейнеры с компонентами BLIP, скомпилировать критичные части через Neuron SDK для запуска на Inferentia2, поместить их в Auto Scaling‑группу на EC2 Inf2 и использовать ELB вместе с CloudWatch‑метриками для масштабирования по реальной нагрузке. Такой подход помогает снизить стоимость «всегда‑включенного» визуально‑языкового инференса без потери точности и доступности.
Источники
Ответы (0)
Пока нет ответов в этой теме.